Buffer模块
缓冲区对象用于表示固定长度的字节序列。许多 Node.js API 支持缓冲区。 Buffer 类是 JavaScript 的 Uint8Array 类的子类,并使用涵盖其他用例的方法对其进行了扩展。 Node.js API 接受普通的 Uint8Arrays,只要 Buffers 也受支持。
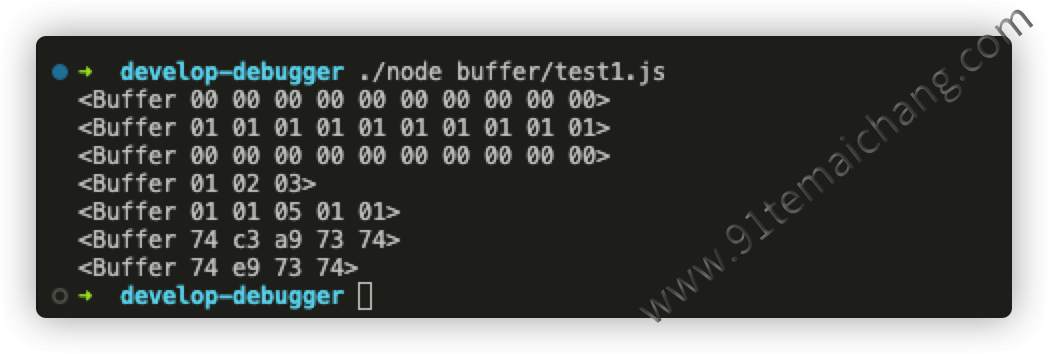
const { Buffer } = require('node:buffer'); const buf1 = Buffer.alloc(10); const buf2 = Buffer.alloc(10, 1); const buf3 = Buffer.allocUnsafe(10); const buf4 = Buffer.from([1,2,3]); const buf5 = Buffer.from([257, 257,5, -255, '1']); const buf6 = Buffer.from('tést'); const buf7 = Buffer.from('tést', 'latin1'); console.info(buf1); console.info(buf2); console.info(buf3); console.info(buf4); console.info(buf5); console.info(buf6); console.info(buf7);
从
我们可以看出Buffer不能直接通过
new关键词来进行构造调用,而是通过其对象上的"静态"方法,来创建对应的Buffer对象,而且Buffer对象的输出,一般是与常规数组对象类似,只不过它是以Buffer开头,而且其中的数据都是以16进制数据类型来展示的!
 是nodejs中buffer模块的组成,接下来将一一分析一波:
是nodejs中buffer模块的组成,接下来将一一分析一波:
Buffer
Buffer是一等函数对象,其内部还是调用对象上的alloc或者是from方法,来创建一个Buffer对象!
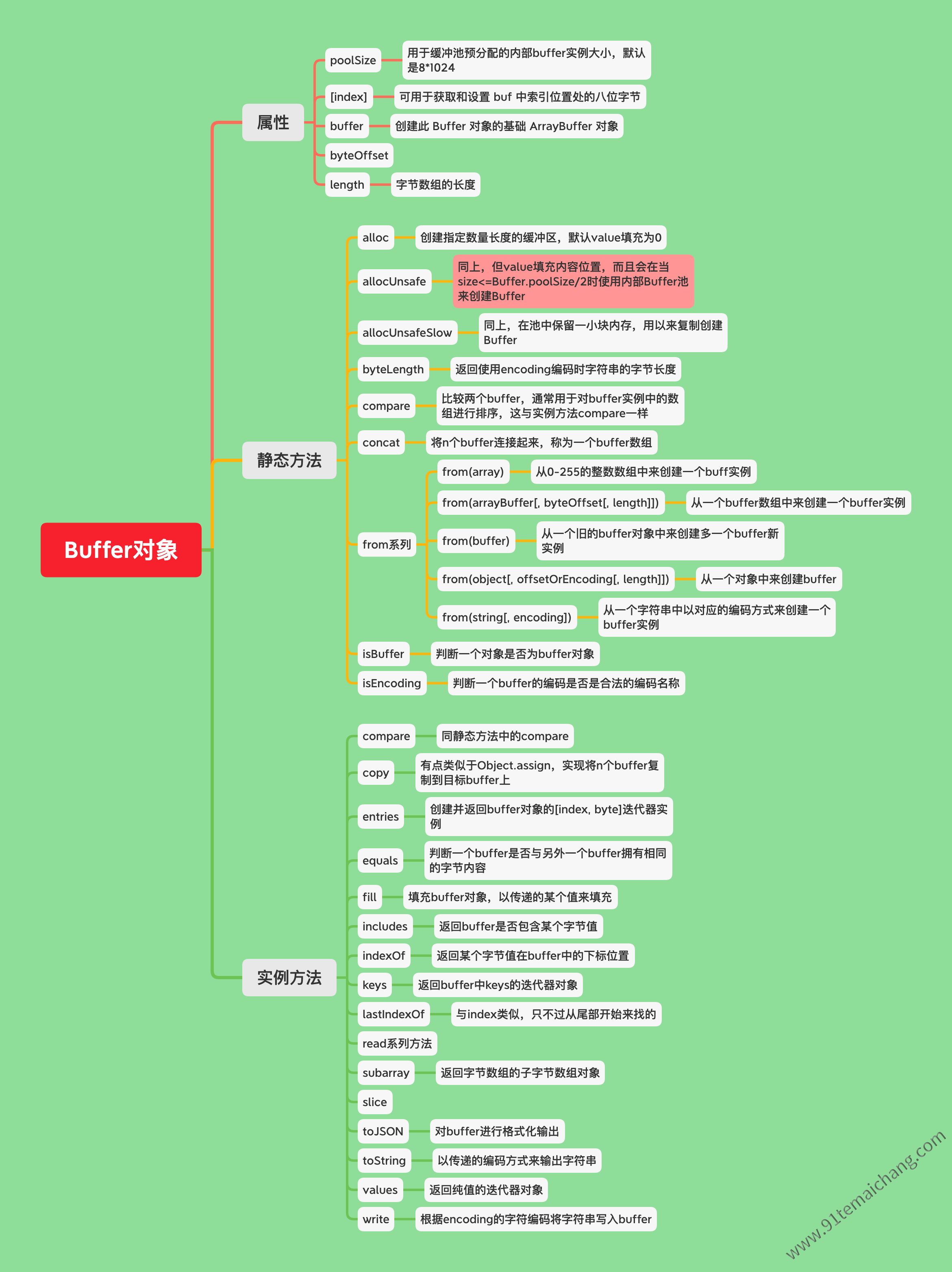
Buffer的创建
在
Buffer提供了一系列的创建Buffer实例方法的静态方法,:point_down: 将一一来分析并对比这些方法之间的异同!Buffer.poolSize的内部 Buffer 实例,该实例用作快速分配使用Buffer.allocUnsafe()、Buffer.from(array)、Buffer.concat()创建的新 Buffer 实例的池。并且仅当 size 小于或等于 Buffer.poolSize >> 1 (Buffer.poolSize 的下限除以 2)时,才弃用 new Buffer(size) 构造函数。使用这个预先分配的内部内存池是调用
Buffer.alloc(size, fill)与Buffer.allocUnsafe(size).fill(fill)之间的关键区别。具体来说,Buffer.alloc(size, fill)永远不会使用内部 Buffer 池,而Buffer.allocUnsafe(size).fill(fill)会在 size 小于或等于 Buffer.poolSize 的一半时使用内部 Buffer 池。差异是微妙的,但当应用程序需要Buffer.allocUnsafe()提供的额外性能时可能很重要。
| 方法定义 | 参数描述 | 方法描述 |
|---|---|---|
| Buffer.alloc(size[, fill[, encoding]]) | size:新缓冲区的所需长度,fill:预先填充的内容,默认是0,encoding:编码方式 | 分配大小字节的新缓冲区,如果填充未定义,缓冲区将被零填充。 |
| Buffer.allocUnsafe(size) | size:新缓冲区的所需长度 | 分配大小字节的新缓冲区,如果 size 大于 buffer.constants.MAX_LENGTH 或小于 0,则抛出 ERR_INVALID_ARG_VALUE。 |
| Buffer.allocUnsafeSlow(size) | size:新缓冲区的所需长度 | 同Buffer.allocUnsafe,以这种方式创建的 Buffer 实例的底层内存未初始化,新创建的 Buffer 内容未知,可能包含敏感数据。 |
| Buffer.from(array) | array:0 – 255 范围内的字节数组 | 使用 0 – 255 范围内的字节数组分配一个新的 Buffer。超出该范围的数组条目将被截断以适应它。 |
| Buffer.from(arrayBuffer[, byteOffset[, length]]) | arrayBuffer:要被共享底层内存的Buffer数组 | 无需复制底层内存来创建ArrayBuffer的视图,也就是共享底层内存 |
| Buffer.from(buffer) | buffer:旧buffer对象 | 从一个旧的buffer中捞出数据来创建新的buffer实例 |
| Buffer.from(object[, offsetOrEncoding[, length]]) | object:支持 Symbol.toPrimitive 或 valueOf() 的对象 | 从一个对象中来创建buffer实例 |
| Buffer.from(string[, encoding]) | string:数据源字符串,encoding:字符编码方式 | 创建一个包含字符串的新 Buffer。 encoding 参数标识将字符串转换为字节时要使用的字符编码 |
 调用 Buffer.alloc() 可能比替代方法 Buffer.allocUnsafe() 慢很多,但可以确保新创建的 Buffer 实例内容永远不会包含来自先前分配的敏感数据,包括可能尚未为 Buffer 分配的数据!!
调用 Buffer.alloc() 可能比替代方法 Buffer.allocUnsafe() 慢很多,但可以确保新创建的 Buffer 实例内容永远不会包含来自先前分配的敏感数据,包括可能尚未为 Buffer 分配的数据!!
当使用 Buffer.allocUnsafe() 分配新的 Buffer 实例时,4 KiB 以下的分配是从单个预分配的 Buffer 中分割出来的。这允许应用程序避免创建许多单独分配的 Buffer 实例的垃圾收集开销。这种方法通过消除跟踪和清理尽可能多的单个 ArrayBuffer 对象的需要来提高性能和内存使用率。但是,如果开发人员可能需要在不确定的时间内从池中保留一小块内存,则可以使用 Buffer.allocUnsafeSlow() 创建一个未池化的 Buffer 实例,然后复制出相关位。
Buffer的编码
当转换Buffer与String时,需要指定转换时所采用的编码格式,如果没有指定,则将采用默认的编码格式!
const { Buffer } = require('node:buffer'); const buf = Buffer.from('hello world', 'utf8'); console.info(buf); console.log(buf.toString('hex')); console.log(buf.toString('base64'));
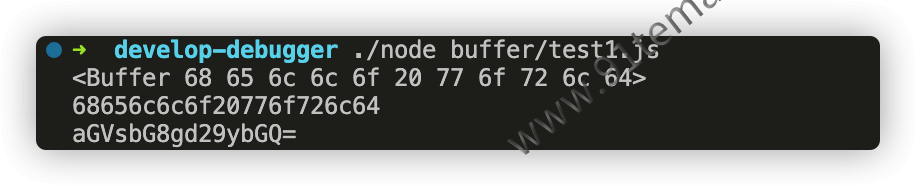
Buffer在编码的时候,允许接收不区分大小写的编码字符串参数!比如UTF-8可以是用utf-8、UTF-8、uTF8来表示!
目前允许的编码格式有:utf8、utf16le、latin1,将Buffer  String称之为解码,将String Buffer 称之为编码!
String称之为解码,将String Buffer 称之为编码!
Node.js 还支持以下二进制到文本的编码。对于二进制到文本的编码,命名约定是相反的:将 Buffer 为字符串通常称为编码,将字符串 Buffer 称为解码。
| 二进制 | 描述 |
|---|---|
| base64 | 从字符串创建缓冲区base64 编码字符串中包含的空格、制表符和换行符等空白字符将被忽略 |
| base64url | 从字符串创建缓冲区时,将 Buffer 编码为字符串时,此编码将省略填充 |
| hex | 将每个字节编码为两个十六进制字符。解码不完全由偶数个十六进制字符组成的字符串时,可能会发生数据截断 |
| ascii | 仅适用于 7 位 ASCII 数据。将字符串编码到 Buffer 时,相当于使用 'latin1'。将 Buffer 解码为字符串时,使用此编码将在解码为“latin1”之前额外取消设置每个字节的最高位 |
| binary | 'latin1' 的别名 |
| ucs2 | “utf16le”的别名 |
Buffer与TypedArrays的关系
Buffer主要继承于原JS环境中的Uint8Array对象,如下图所示:
 这意味着所有在TypedArray对象上的所有方法都可以在Buffer上使用,
这意味着所有在TypedArray对象上的所有方法都可以在Buffer上使用, Buffer API与TypedArray API 之间存在细微的不兼容!如下所示:
| 方法 | Buffer | TypedArray |
|---|---|---|
| slice() | 通过免复制拷贝的方式来创建源数组的一部分视图查看 | 创建源数组的一部分拷贝 |
| subarray() | - | 用于在Buffer以及其他TypedArray上实现slice的行为 |
| toString() | 与TypedArray的toString()不兼容,是重新写的 | 直接输出当前对象的内容展现形式 |
| indexOf() | 允许接收额外的参数 | 只有一参数 |
 将 Buffer 传递给 TypedArray 构造函数将复制 Buffers 内容,解释为整数数组,而不是目标类型的字节序列
将 Buffer 传递给 TypedArray 构造函数将复制 Buffers 内容,解释为整数数组,而不是目标类型的字节序列
import { Buffer } from 'node:buffer';
const buf = Buffer.from([1, 2, 3, 4]);
const uint32array = new Uint32Array(buf);
console.log(uint32array);
// Prints: Uint32Array(4) [ 1, 2, 3, 4 ]
Buffer与迭代器
Buffer实例可以被迭代器来访问,通过
for...of语法来遍历访问到import { Buffer } from 'node:buffer'; const buf = Buffer.from([1, 2, 3]); for (const b of buf) { console.log(b); } // Prints: // 1 // 2 // 3
Blob
Blob封装了可以在多个工作线程之间安全共享的不可变原始数据!它也是buffer中所暴露出来的一个模块,其使用方式如下:
const blob = new buffer.Blob([sources[, options]]);
- sources: 可以是
string、ArrayBuffer、TypedArray、DataView、Blob对象,也可以是这由这些对象所组成的数组,或者是由这些对象混合组成的数组,它们都将被存储在blob对象中!- options: 包含有endings以及type属性,两者都是string类型,endings可以是
transparent或者native,当设置为native时代表其尾部将由所在系统来定(通过node:os的EOL);而type则代表内容类型,目的是让type传达数据MIME媒体类型,但不执行类型格式的验证。
Blob与MessageChannel
创建对象后,可以通过 MessagePort(worker_threads中的模块,用多线程的方式来执行js) 将其发送到多个目的地,而无需传输或立即复制数据。仅当调用 arrayBuffer() 或 text() 方法时,才会复制 Blob 包含的数据
const { Blob, Buffer } = require('node:buffer');
const { setTimeout } = require('node:timers/promises');
const { MessageChannel } = require('node:worker_threads');
const blob = new Blob(['hello blob']);
const mc1 = new MessageChannel();
const mc2 = new MessageChannel();
mc1.port1.onmessage = async ({ data }) => {
console.log(await data.arrayBuffer());
mc1.port1.close();
};
mc2.port1.onmessage = async ({ data }) => {
await setTimeout(1000);
console.log(await data.arrayBuffer());
mc2.port1.close();
};
mc1.port2.postMessage(blob);
mc2.port2.postMessage(blob);
// The Blob is still usable after posting.
blob.text().then(console.log);