http相关
http模块
首先先了解该模块的一个组成部分,如
图所示:
,这边对应整理为自己习惯的脑图:
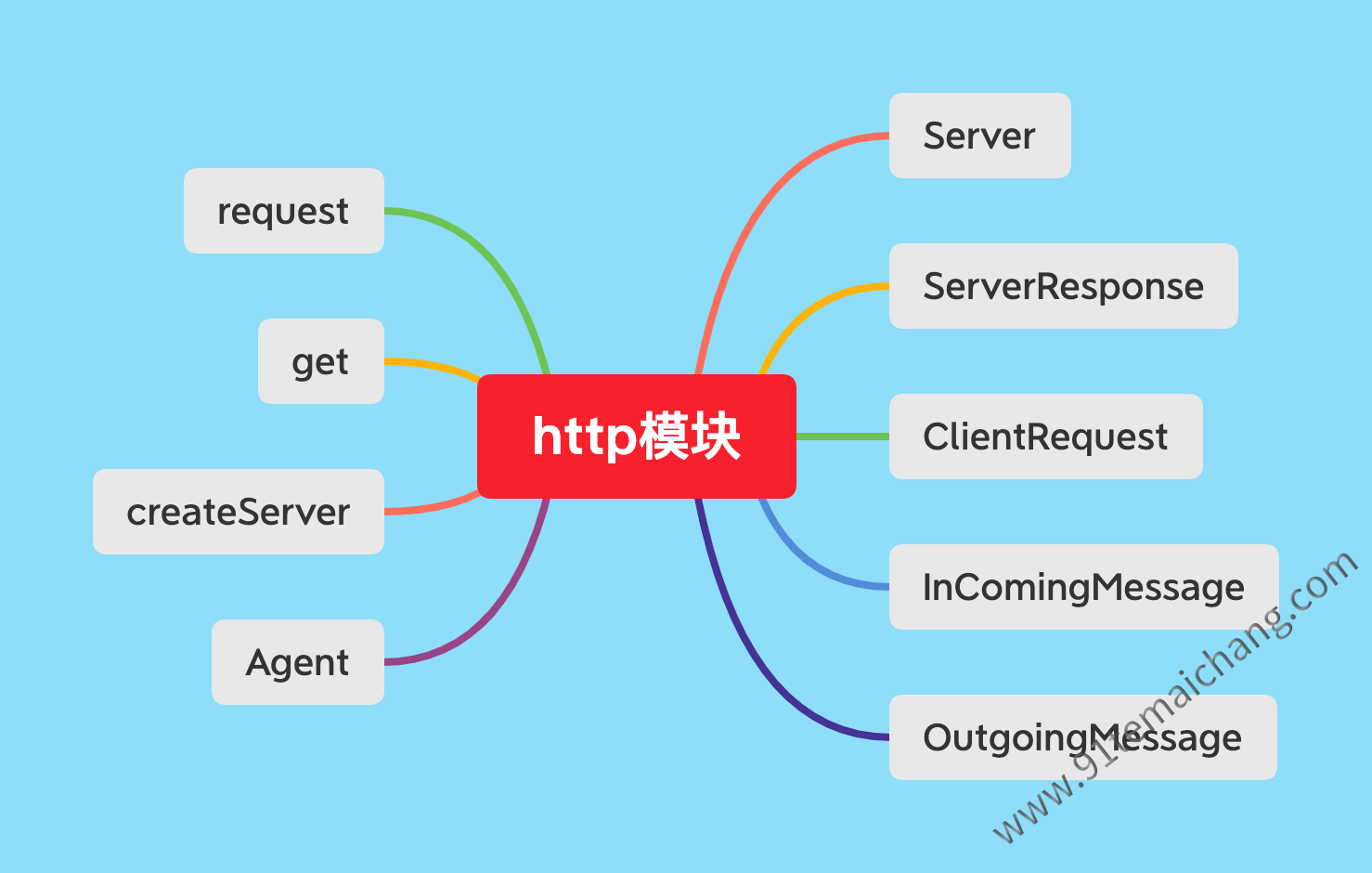
 需要明确的一点是,我们的任何一个主机它既可以作为服务端,也可以做为客户端来使用,这取决于实际的应用场景, 将根据对应的两种不同场景来使用并分析关于对应场景下的http模块成员的一个使用方式
需要明确的一点是,我们的任何一个主机它既可以作为服务端,也可以做为客户端来使用,这取决于实际的应用场景, 将根据对应的两种不同场景来使用并分析关于对应场景下的http模块成员的一个使用方式
作为服务端来使用
一切以createServer方法开始,该方法其实就是简单的调用
new Server()来创建一个http服务对象,其底层就是创建一个tcp的长连接服务来等待操作!const http = require('node:http'); const server = http.createServer((req, res) => { res.end('okay); }); server.listen(3000);
这里我们创建了一个server服务,然后让该服务监听3000端口,当我们访问3000端口的任何资源时,都将返回'okay'的字符串
 那么这里这个过程发生了什么事情呢?还有,这个
那么这里这个过程发生了什么事情呢?还有,这个Server对象它是怎样的一个对象呢?
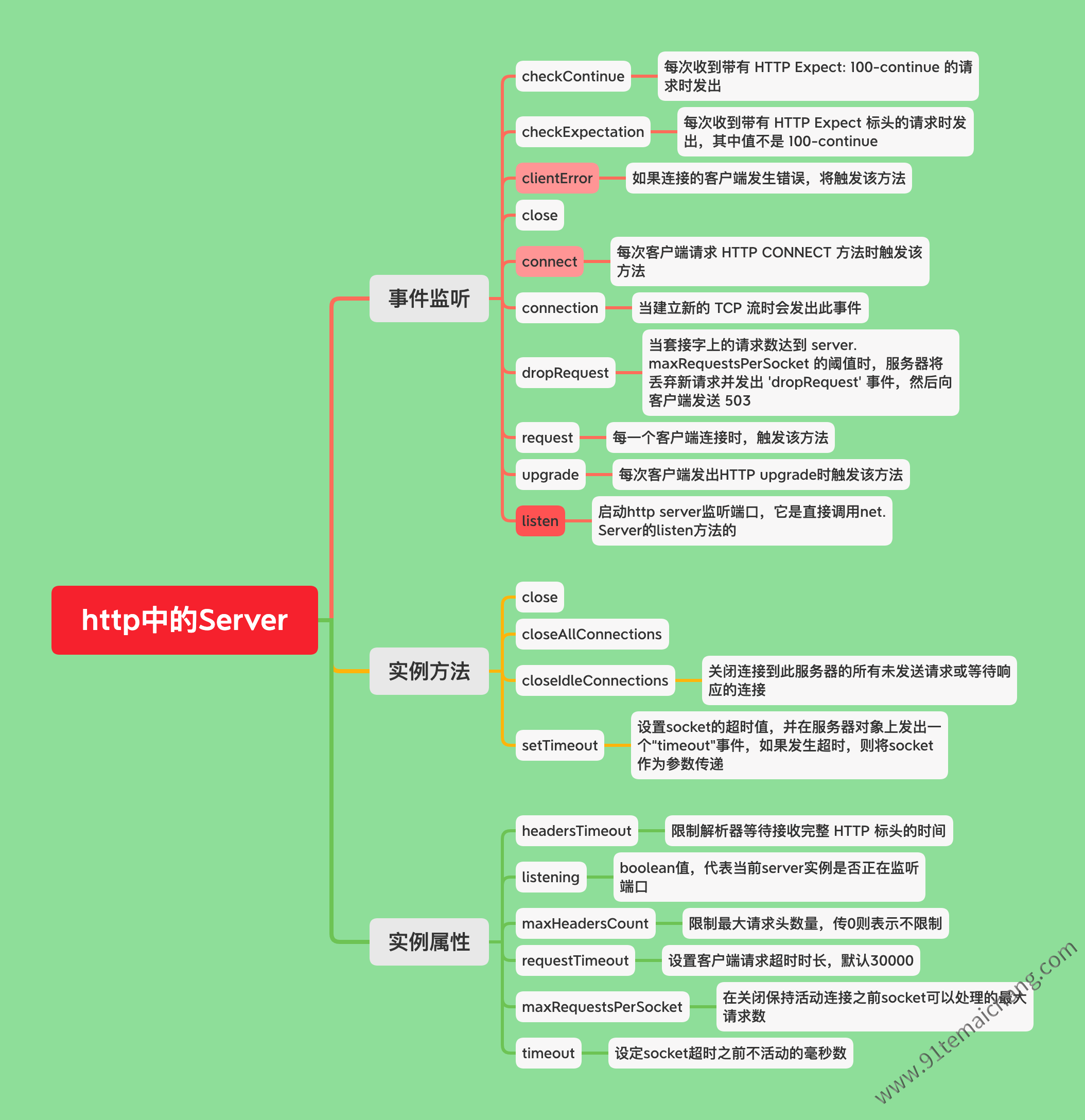
Server对象

首先从上面这里可以看出Server对象继承于
net.Server对象,而该对象继承于EventEmitter对象,使得其拥有了on/emit等方法以及对应的变量,而且关键拥有了_handle变量,使得它能够监听底层的的通讯,拥有了对应的回调通讯机制; 然后,如果构造调用该方法的时候,传递了这个回调监听方法的话,那么将会对当前对象的request监听事件设置为这个回调方法,也就是在接收到每一个来自于客户端的请求的同时,触发该request回调方法; 接着,对该Server对象设置connection监听事件,这个是主要可用于后面如果需要将该Server对象给配置成为一代理服务,用于直接处理转发用的时候,所触发的动作 关于语法使用的介绍const server = new Server(options, requestListener);关于options参数的定义如下:
| 变量 | 描述 | 默认值 |
|---|---|---|
| IncomingMessage | 指定要使用的IncomingMessage类 | IncomingMessage |
| ServerResponse | 制定要使用的ServerResponse类,对于扩展默认的ServerResponse很有用 | ServerResponse |
| maxHeaderSize | 请求头的最大长度值 | 16KB |
| insecureHTTPParser | 使用不安全的http解析器来解析无效的http header | false |
| requestTimeout | 客户端到服务端请求的超时时长 | 300000 |
| headersTimeout | 客户端接受完整http header的超时时长 | 60000 |
| connectionsCheckingInterval | 以毫秒为单位设置间隔值来检查请求中的header以及请求 | 30000 |
| keepAliveTimeout | 服务器在完成写入最后一个响应之后,销毁socket之前需要等待的时长 | 5000 |
| noDelay | 在收到新的连接时是否激励禁用Nagle算法 | true |
| keepAlive | 设置是否在接收到客户端连接时在socket上启用keep-alive功能 | false |
| uniqueHeaders | 当且仅当第一次发送的header头列表 | true |
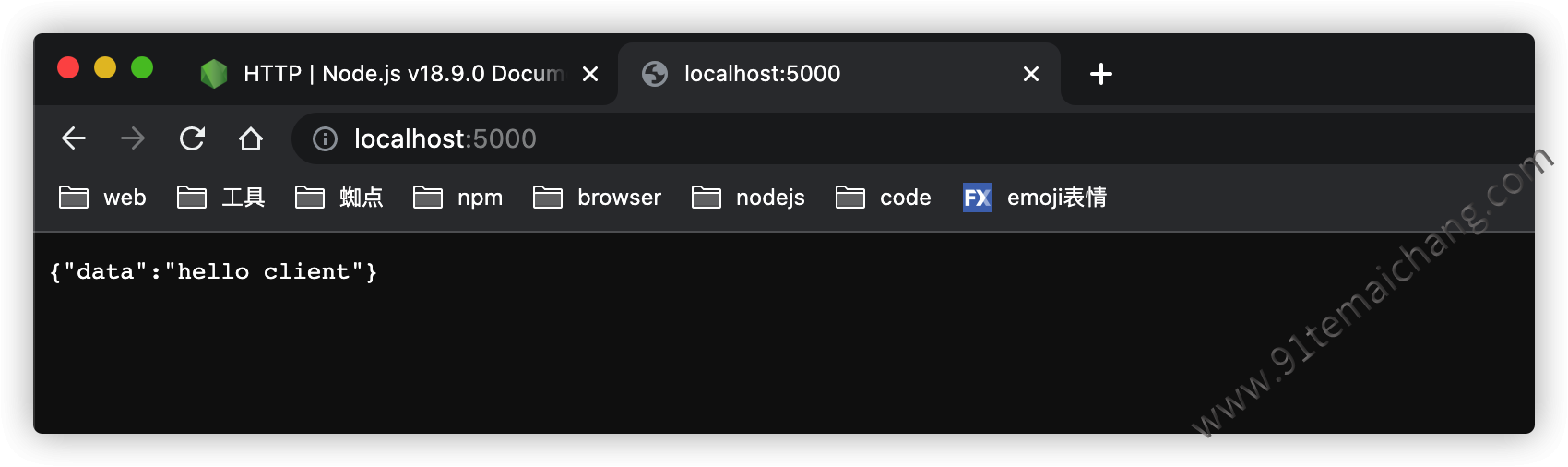
正常情况下,可以无需配置options参数,而直接使用,如下代码所示:
const http = require('node:http');
const server = http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'application/json'
});
res.end(JSON.stringify({
data: 'hello client'
}));
});
server.listen(5000);
 这里我们拆分为两个动作:
这里我们拆分为两个动作:
创建一个server对象并设置监听
 创建了一个
创建了一个Server对象,并传递了一个请求监听函数requestListener,该函数接收两个参数,第一个代表客户端请求对象ClientRequest,第二个代表服务端响应对象ServerResponse,这与直接在这个Server实例上设置request事件监听一样!然后对这个Server实例调用listen方法,然后针对5000端口设置监听,该方法直接调用从net.Server上继承而来的方法,采用底层的设置监听的动作: 调用其setupListenHandle方法,并创建一_handle对象来处理监听响应!服务端响应
 一旦有新的客户端连接访问过来的时候,触发server实例对象的onconnection方法,在此时,如果超过当前server的最大连接数(假如
一旦有新的客户端连接访问过来的时候,触发server实例对象的onconnection方法,在此时,如果超过当前server的最大连接数(假如  设置maxConnections属性)的话,将会触发
设置maxConnections属性)的话,将会触发drop方法,忽略连接操作!然后进入server的new http connection方法,这也就是在创建Server对象的时候,设置的connection事件所触发的,参数为当前服务的底层socket对象,并对这个socket对象设置httpparser请求解析对象,然后对该socket对象追加一系列的关于http方面的操作,比如有data、error、end、drain、resume、pause监听动作的重写动作,这即保证了原有的socket的干净,又可以在原有的socket对象上使用自身的额外的重载方法,这是一种在运行时追加额外的逻辑动作的编程模式!
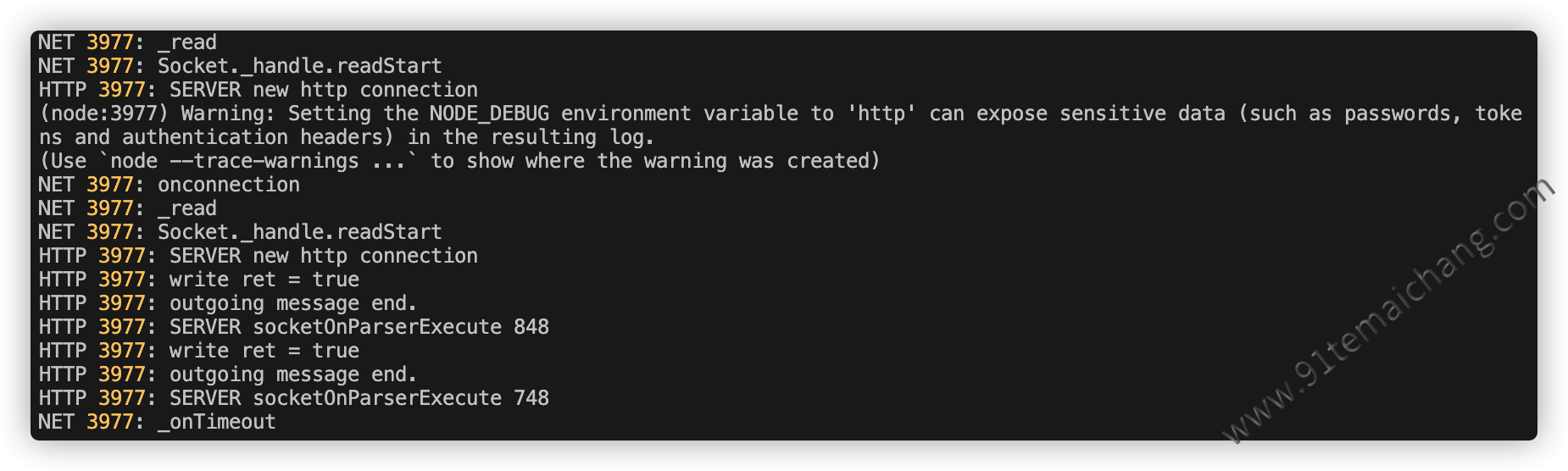
从 的输出日志我们可以看到,write相关的操作被调用了两次,这里其实是因为我们针对该端口上进行的监听,任何往这个端口上访问的资源,都会返回同样的结果,而我们这里是用的浏览器作为客户端测试输出结果的,浏览器默认也会请求同一个地址下的ico图标,这个图标目前也是返回的一样的结果,因此write方法就被调用了两次!!
在创建一个Server实例的时候,传递的callback回调函数,用于监听request动作的,该函数  个参数,第一个是
个参数,第一个是ClientRequest,第二个是ServerResponse,分别代表着接收到的客户端发起的请求以及服务端响应对象
关于这个服务对象,这边补充总结多一个关于该对象的组成结构图:
服务端响应对象ServerResponse
ServerResponse继承于
OutgoingMessage对象,使用其提供的header操作相关api来存储的 由http模块内部所创建的,比如createServer方法中的options参数中的ServerResponse,主要用于设置一个请求响应体的一个响应动作,也可以是作为createServer的request事件中的第二个参数来返回,代表相应体对象,包括有响应头、响应体、超时时长等等
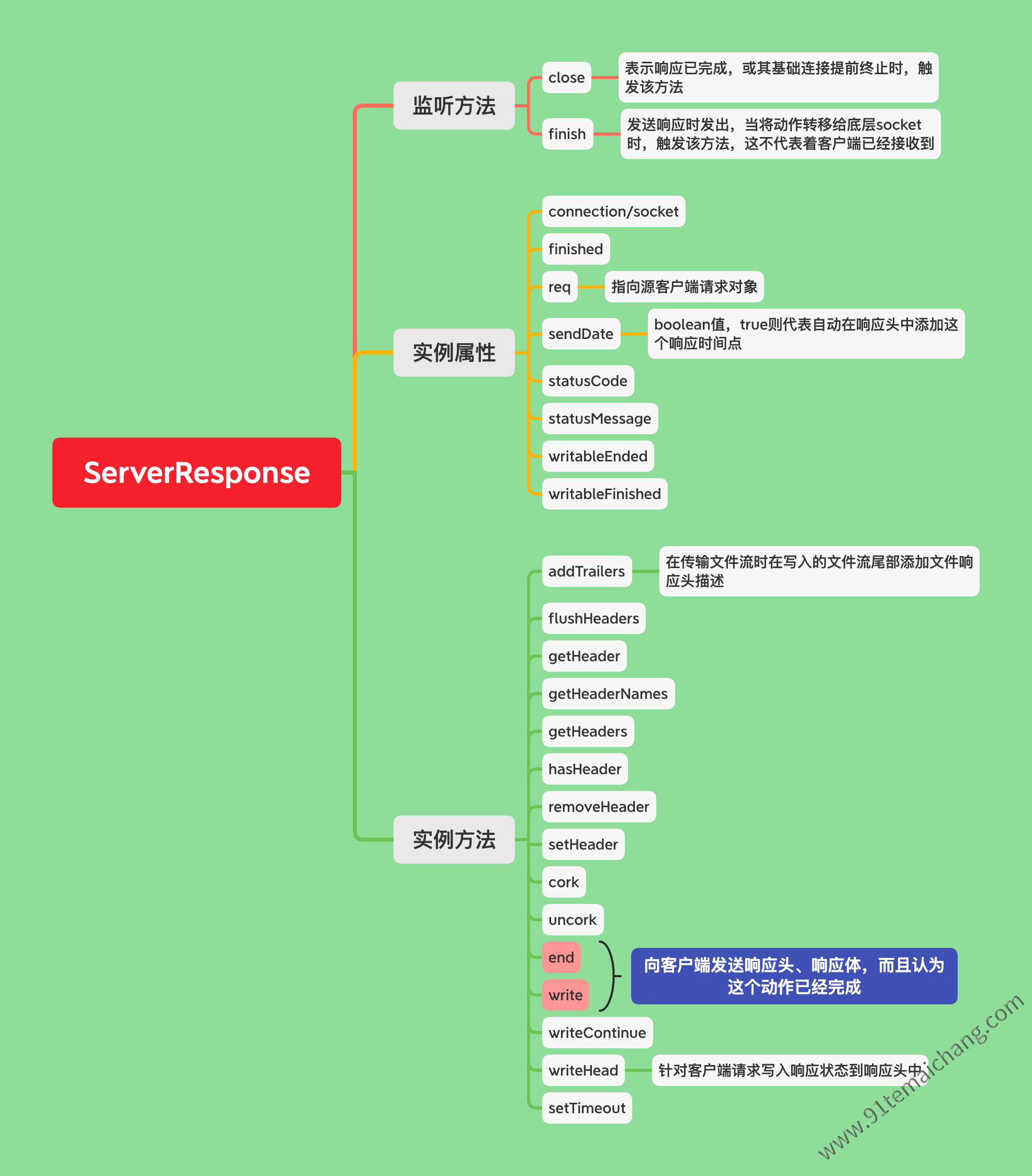
ServerResponse中关键的两个方法:writeHead + write/end
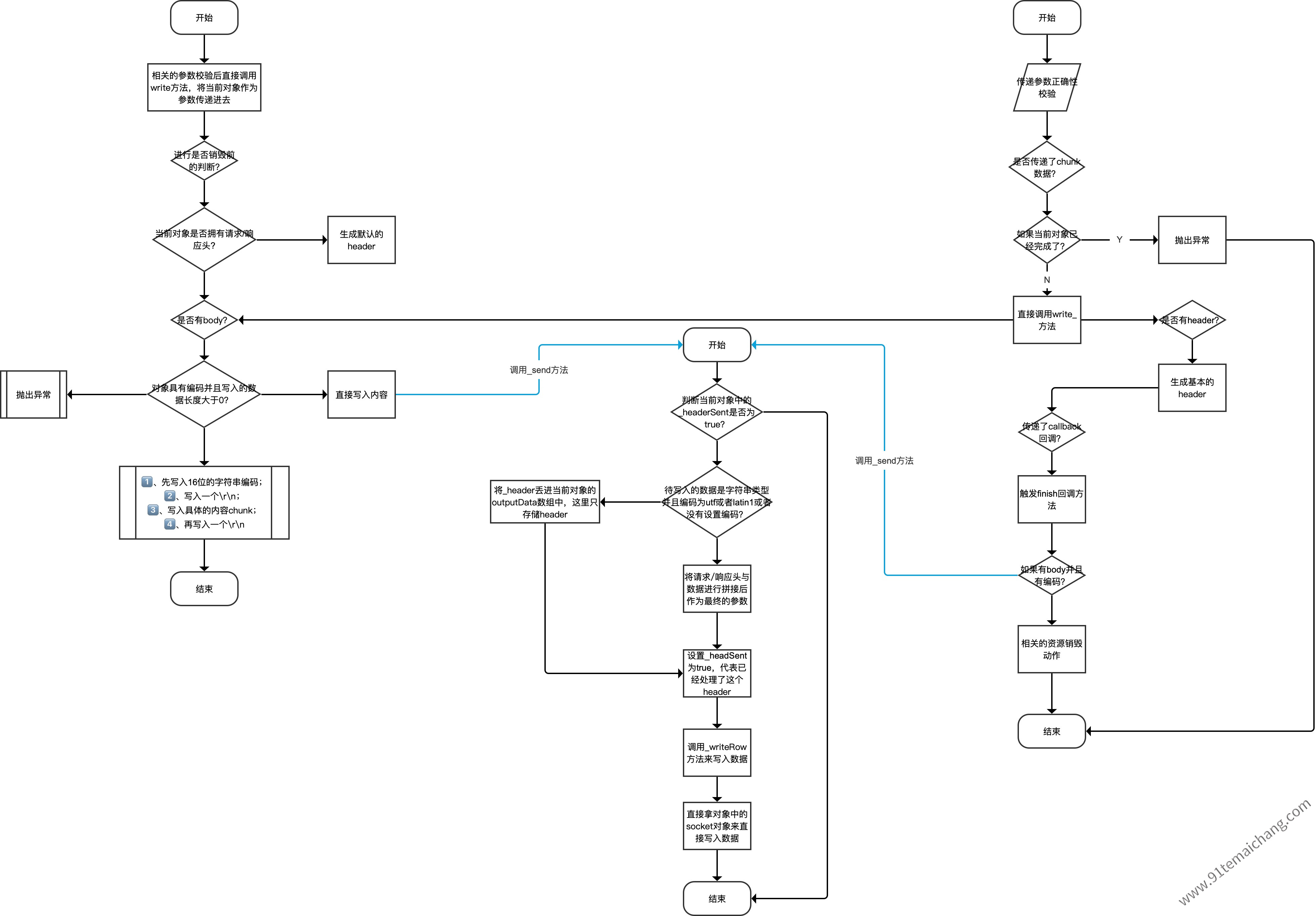
 . writeHead: 对一个请求发送响应头信息,代表请求资源响应结果,该方法只能被调用一次,因为一旦调用,就意味着已经先告诉客户端当前资源的一个响应结果状态了,并且需要在最后的时刻,调用end()方法,代表结束当次响应!
. write: 可用来对socket写入数据,可用来写入文件续传功能,只在第一次报文传输时,发送第一个chunk,并携带上响应头,然后后续的chunk则不传递这个响应头!
. writeHead: 对一个请求发送响应头信息,代表请求资源响应结果,该方法只能被调用一次,因为一旦调用,就意味着已经先告诉客户端当前资源的一个响应结果状态了,并且需要在最后的时刻,调用end()方法,代表结束当次响应!
. write: 可用来对socket写入数据,可用来写入文件续传功能,只在第一次报文传输时,发送第一个chunk,并携带上响应头,然后后续的chunk则不传递这个响应头!
作为客户端来使用
客户端请求对象ClientRequest
ClientRequest对象在http模块中是通过http.request()方法返回的一个对象,代表一个正在进行中的请求,它的header已进入排队阶段,可使用getHeader、setHeader、removeHeader等api来改变发起的请求的请求头。在实际的数据传输时,其实是在request.end()或者数据块发送的时候发出去的。
response,用来监听响应到的数据,而这个response监听器的回调函数,其参数是一个IncomingMessage对象,而且在response事件响应期间,我们还可以将这个监听器data添加到响应对象中,来监听关于数据事件ClientRequest对象添加这个response监听事件,那么当前请求所发起的响应将会被忽略,而如果添加了的话,则必须要通过IncomingMessage对象的read()方法在流可读的情况下,读取到对应的数据,还可以通过这个resume()来进行消费数据,因为这个ImcomingMessage对象它是一个可读流对象,而如果没有通过消费的方式来消耗这个可读流的话,那么请求到的数据都将会进入到缓冲区中,缓冲区是
const http = require('node:http');
// 以下是针对每个客户端的访问,来请求另外一个服务,这里以百度为例
const tempReq = http.request({
hostname: 'www.baidu.com',
port: 80,
method: 'GET'
}, res => {
console.info('发起的请求响应了');
res.on('data', chunk => {
console.info(chunk.toString());
});
});
tempReq.on('error', e => {
console.error('出现异常了', e);
})
tempReq.end();
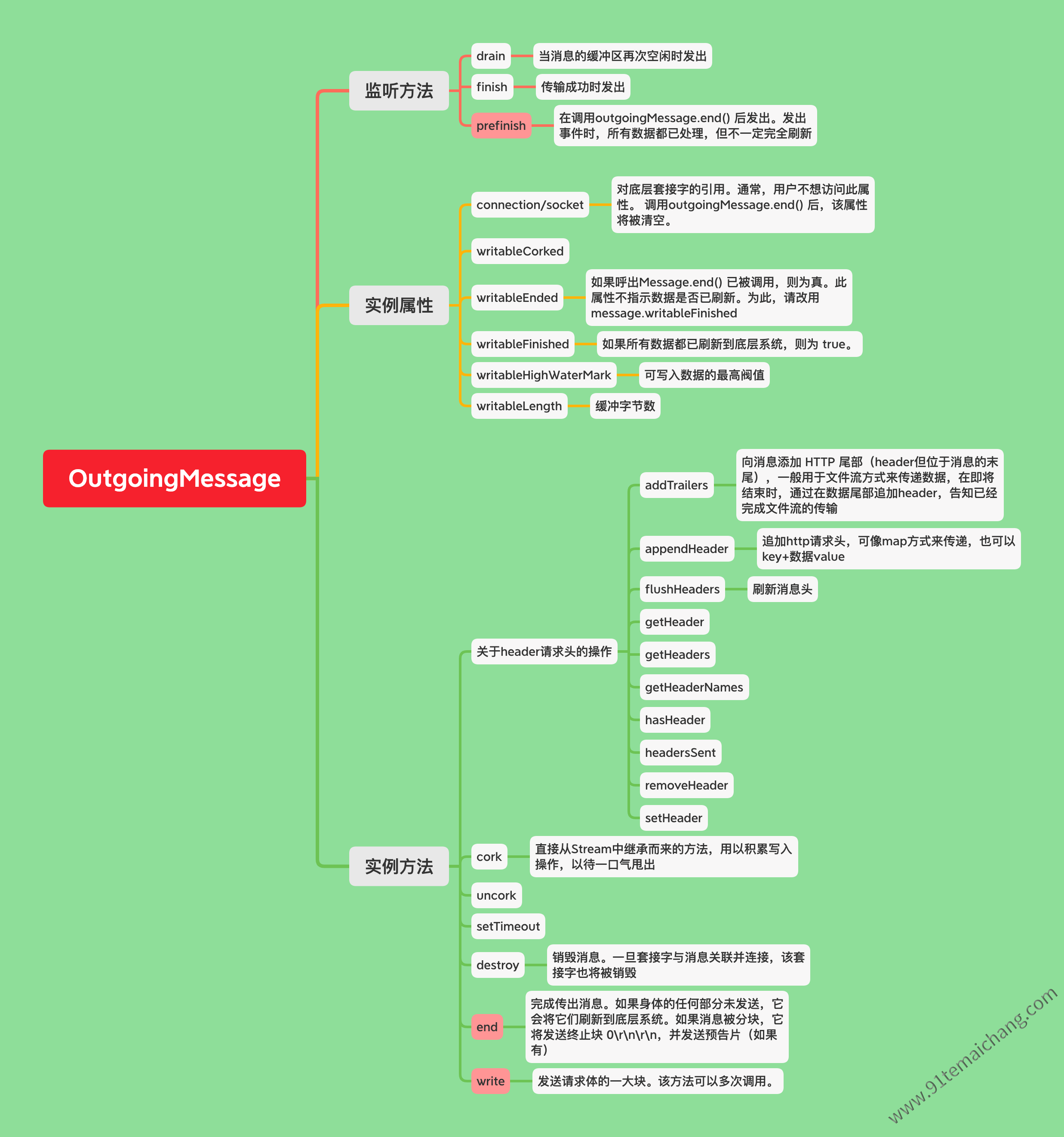
ClientRequest对象其实是继承了OutgoingMessage对象,该对象是一个Stream流对象,是一个全双工的流对象,可读可写,关于该对象,其主要包含outputData属性,用以作为缓存并即将pull出去的一个数据载体,主要是请求提所包含的相关元素,另外,还包含有header、body、socket,ClientRequest对象大部分的api都来自于这个OutgoingMessage
OutgoingMessage发送的流描述
对发送出去的流对象的描述,且提供了对流的操作(可读可写的原因),当我们通过
ClientRequest.end()方法来结束客户端的数据写入时,其实是调用的OutgoingMessage的end()方法,来结束一个请求流的写入动作,其底层是通过其socket对象来进行的最终的write操作的,outputData它是一个数组对象,其成员的组成结果如[{ data, encoding, callback }]用来缓存每一次的写入的数据、数据编码、以及写入成功后的回调
关于这个OutgoingMessage对象,我们需要如何使用呢?它都有哪些方法以及数据可以给我们来使用的呢?
IncomingMessage客户端请求响应对象
IncomingMessage对象由new http.Server()或者http.request()方法来返回,用于指代服务端的响应对象,当由new http.Server()方法来监听时,在其callback回调函数中的第一个参数返回,指代当前所创建的Server服务响应对象,而当使用http.request()方法来创建一个ClientRequest客户端请求时,通过在创建时传递的requestListener或者是通过设置request事件监听的方式,从回调函数的参数中找到指向的IncomingMessage简而言之,就是作为服务端请求的响应以及作为客户端请求的响应对象的抽象,继承于stream.Readable对象,说明它是可读的对象,其底层拥有的net.socket对象主要用于网络通讯媒介!!
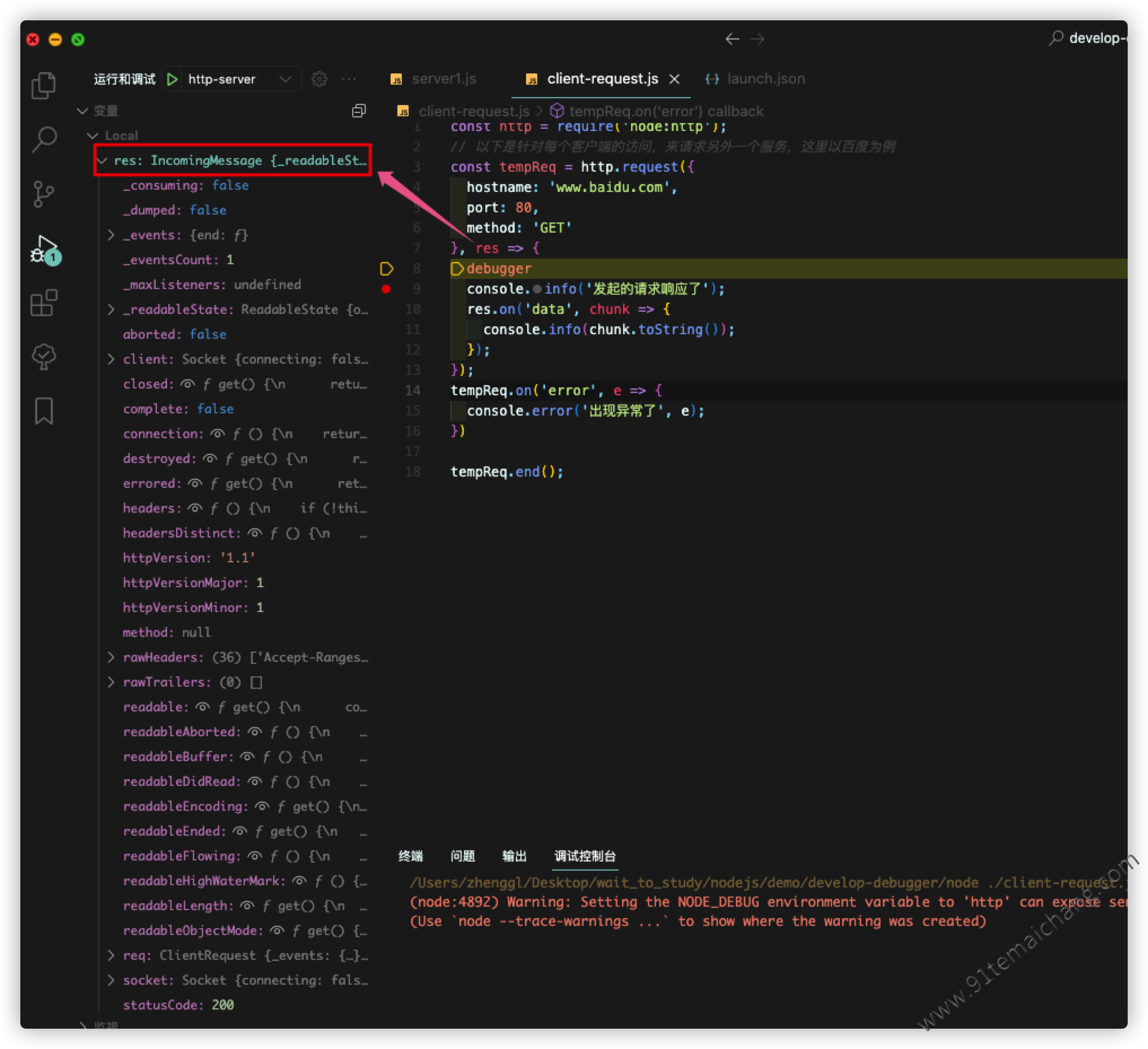 这里通过监听
这里通过监听ClientRequest对象的request方法,可以清楚地了解到关于在node模块中发起一http请求动作后,它的一个执行过程!!
关于这个IncomingMessage对象,我们需要如何来使用?它有哪些方法、属性以及api可以供我们来使用的呢?
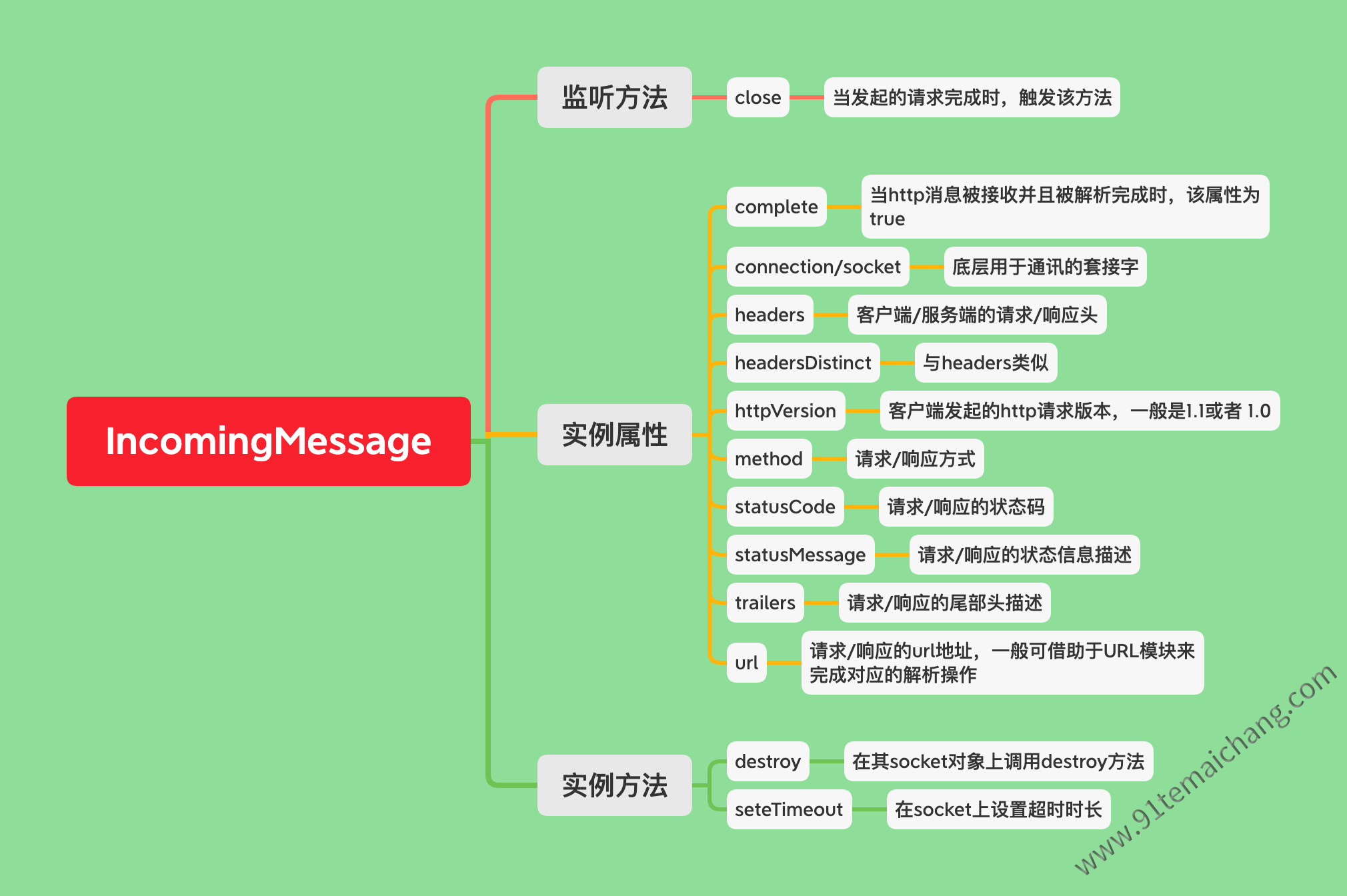
从 我们可以看出这个IncomingMessage对象,更像是一个http请求者/响应者的抽象代表,其包含了一系列与http请求相关的所有因素,比如有请求/响应头、请求/响应体、请求/响应方式、请求/响应地址等等!!
Agent对象
负责管理http客户端的连接持久性与重用性,目的是为每次的请求重用一个socket连接,节省socket资源,通过给制定的主机名+端口号来维护(主机名:端口号作为key的方式)到一个队列中,直到队列为空,简单理解,就是一个map的缓存控制机制!
http模块中的相关api方法:requst、get、socket.connect中都有这个Agent对象来作为参数进行传递,而如果在使用的时候,没有传递对应的Agent对象的话,则采用的是全局的一个GlobalAgent对象来使用的,该全局对象的定义如下:{ "keepAlive": true, "scheduling": false, "timeout": 5000 }
额外知识补充
在学习node中的
http模块的时候,我们发现它有不少的请求方式,我们在平时开发学习过程中比较少涉猎到,本小节将进行一一解读
常见请求方式:HTTP_METHOD
首先,先甩出关于HTTP_METHOD的相关枚举
然后在结合在
MND上的学习,并整理了一下经常使用的相关网络请求方法对比表格
| 请求方式 | 目的/描述 | 拥有请求体 | 拥有响应体 | 是否可缓存 | 是否支持html表单 |
|---|---|---|---|---|---|
| get | 请求制定的资源 |  |
 |
|
|
| head | 只请求头部信息,比如可以用来请求一个文件的头部信息获取文件大小 | |
|
|
|
| options | 获取目标服务器所支持的通讯方式,也称为嗅探 | |
|
|
|
| patch | 用于对资源的部分修改 | |
|
|
|
| post | 发送数据给服务器,其请求体由content-type决定 |
|
|
|
|
| put | 使用请求提中的payload载体来创建或替换资源 | |
|
|
|
| trace | 提供了通向目标资源的来回闭环路线测试 | |
|
|
|
| connect | 提供客户端与目标资源的双向沟通通道,比如可以将自己的服务器作为代理,用来做跳板服务,有客户端与目标资源直接通讯 | |
|
|
|
| delete | 删除指定的资源 | |
|
|
|
创建一个服务参数详解: http.createServer([options], requestListener)
关于该方法中的参数描述如下:
| 参数 | 描述 | 默认值 |
|---|---|---|
| IncomingMessage | 自定义的IncomingMessage对象,一般可从默认的IncomingMessage对象继承来作为自己的 |
IncomingMessage |
| ServerResponse | 自定义的服务器响应对象 | ServerResponse |
| requestTimeout | 设置从客户端接收整个请求的超时时长 | 300000 |
| headersTimeout | 设置从客户端接收完整HTTP请求头的超时时长 | 60000 |
| keepAliveTimeout | 服务端在完成写入最后一个响应之后,销毁socket等待时长 | 5000 |
| connectionsCheckingInterval | 设置检查不完整请求中的请求体以及请求头超时时长 | 30000 |
| insecureHTTPParser | 设置是否允许接收不安全的解析器 | false |
| maxHeaderSize | 设置最大的请求头大小 | 16KB |
| noDelay | 接收到新的连接时立即禁用Nagle算法 | true |
| keepAlive | 设置是否在接收到新的连接后立即在socket上启用keep-alive功能 | false |
| keepAliveInitialDelay | 设置socket为keep-alive的延迟时长 | 0 |
| uniqueHeaders | 设置响应时应该传递的请求头 | [] |
关于ServerResponse的writeHead/write/end方法详解
net.Server的,那么为什么我们在使用这个http模块中的Server的时候,它却能够响应到带有一定的http响应头的相关操作的呢?:point_right: 关键在于http的Server中封装了关于既定请求/响应头的组装,能够在我们发起请求/响应时,进行对应header的生成与响应
ServerResponse.writeHead方法的过程
首先,先看一下关于这个writeHead方法的定义:
ServerResponse.prototype.writeHead = function(statusCode, reason, obj)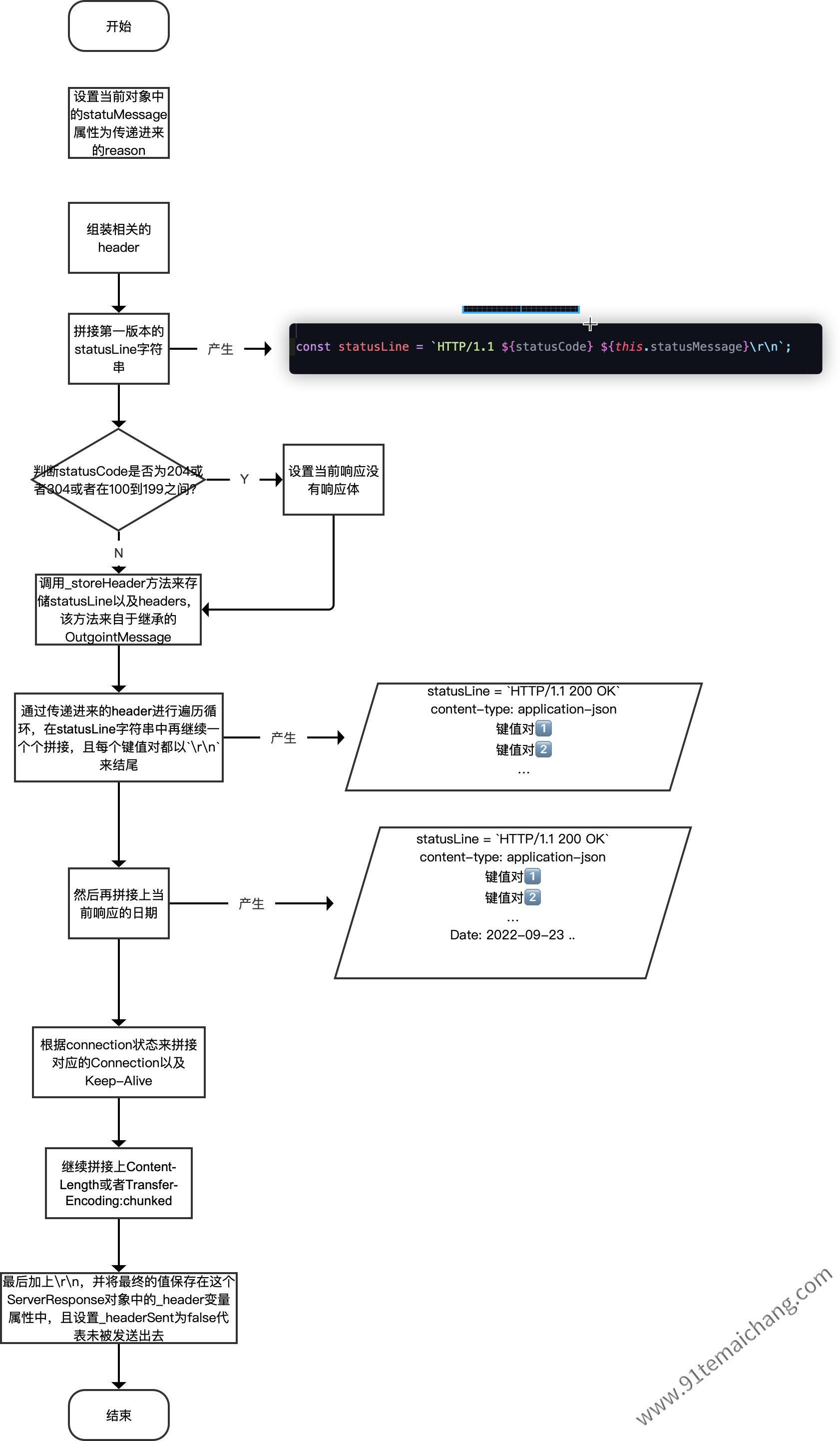
OutgoingMessage对象所提供的基础api服务,来往目标对象中的_header属性赋值,以及设置_headerSent属性,用于后续write用的!
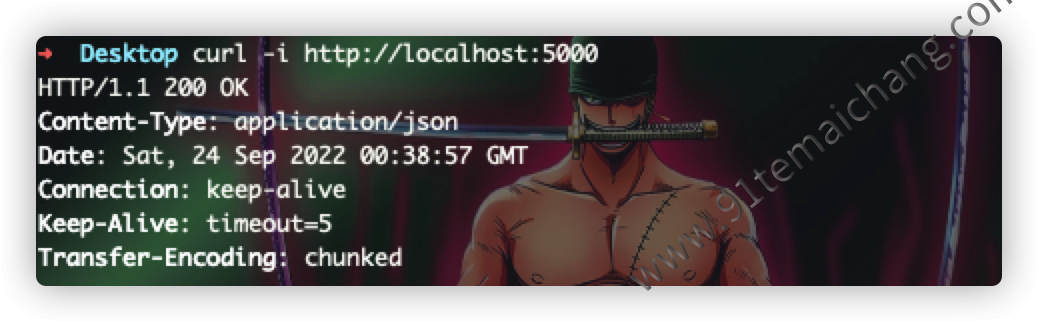
ServerResponse.write  ServerResponse.end
ServerResponse.end
ServerResponse对象所提供,而是从OutgoingMessage对象中继承而来的OutgoingMessage.prototype.end = function end(chunk, encoding, callback)OutgoingMessage.prototype.write = function write(chunk, encoding, callback)两者的调用参数一致,但两者