body-parser
针对客户端的请求,根据客户端所传递的
content-type的不同类型,对应动态提供不同的parser解析器,由对应的解析器来提供对应的解析操作,将解析后的数据存储到req.body属性中,由于这里
req从头到尾都是同一个对象,因此在req.body上所存储的信息,都将会被存储下来,且会借由中间件机制,传递到后续的每一个中间件中
body-parser的使用
const http = require('http');
const connect = require('connect');
const bodyParser = require('body-parser');
const app = connect();
app.use(bodyParser.json());
app.use((req, res) => {
res.setHeader('Content-Type', 'text/html; charset=utf-8');
res.write('你提交的数据是: \n');
console.info(req.body);
res.end(JSON.stringify(req.body, null, 2));
});
http.createServer(app).listen(3000);
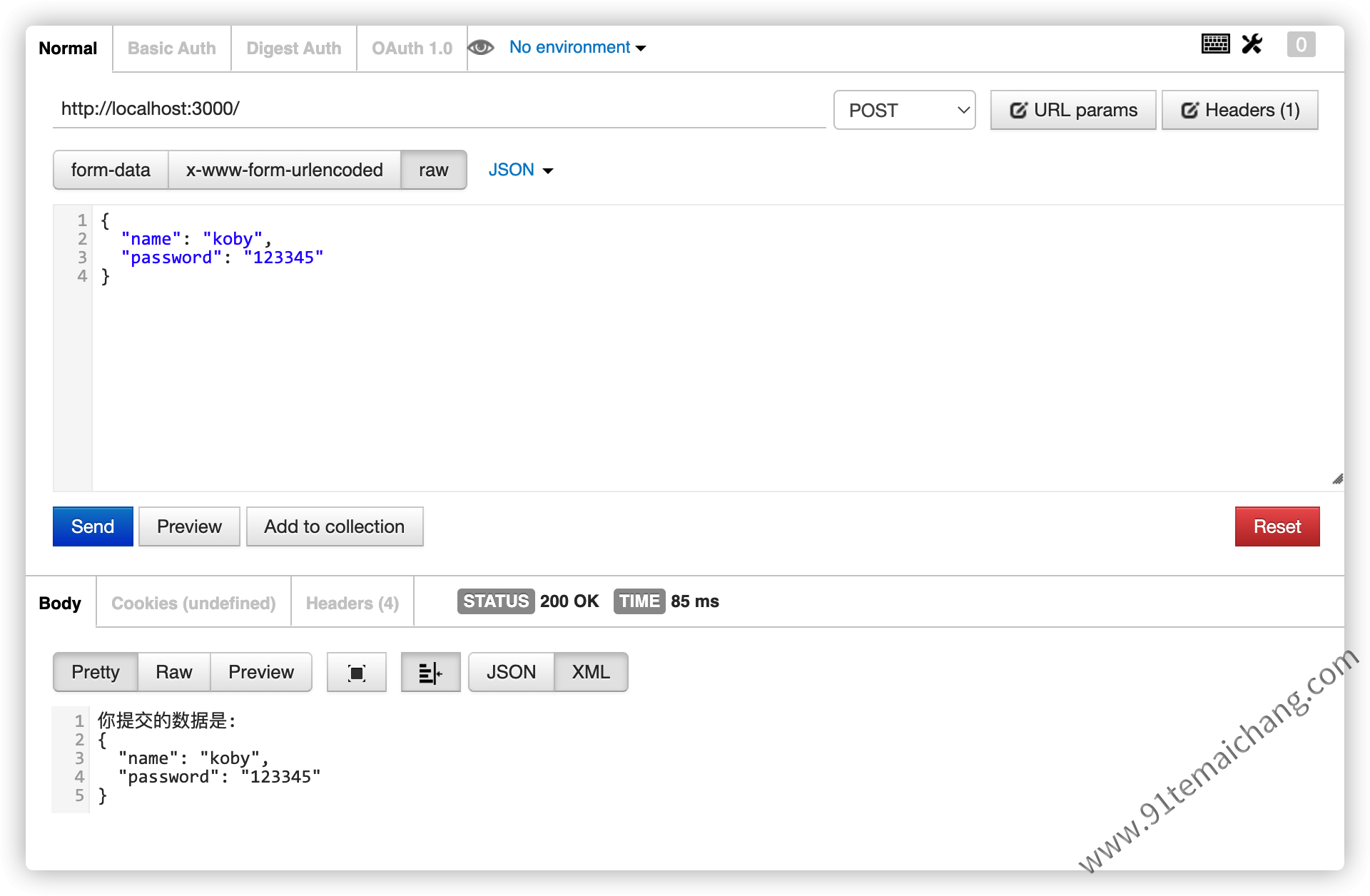
 有时为了让一个响应能够同时响应到不同的
有时为了让一个响应能够同时响应到不同的content-type的解析,可以同时设置不同的parser解析器,也就是让一个资源请求同时支持不同的type请求!!
app.use(bodyParser.urlencoded({ extended: false }));
app.use(bodyParser.json());
app.use(bodyParser.text());
app.use(bodyParser.raw());
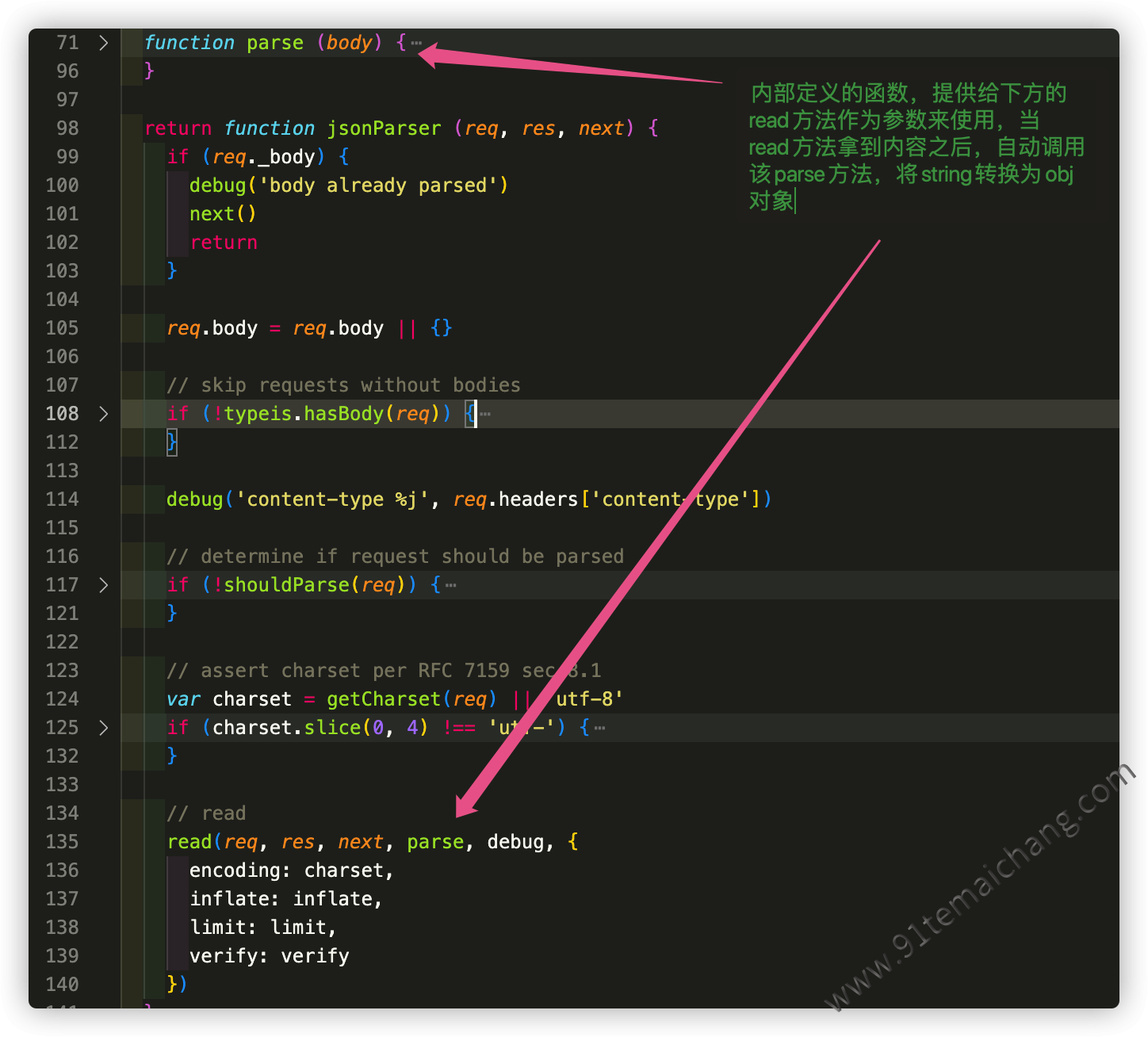
body-parser源码解析(以json为例)
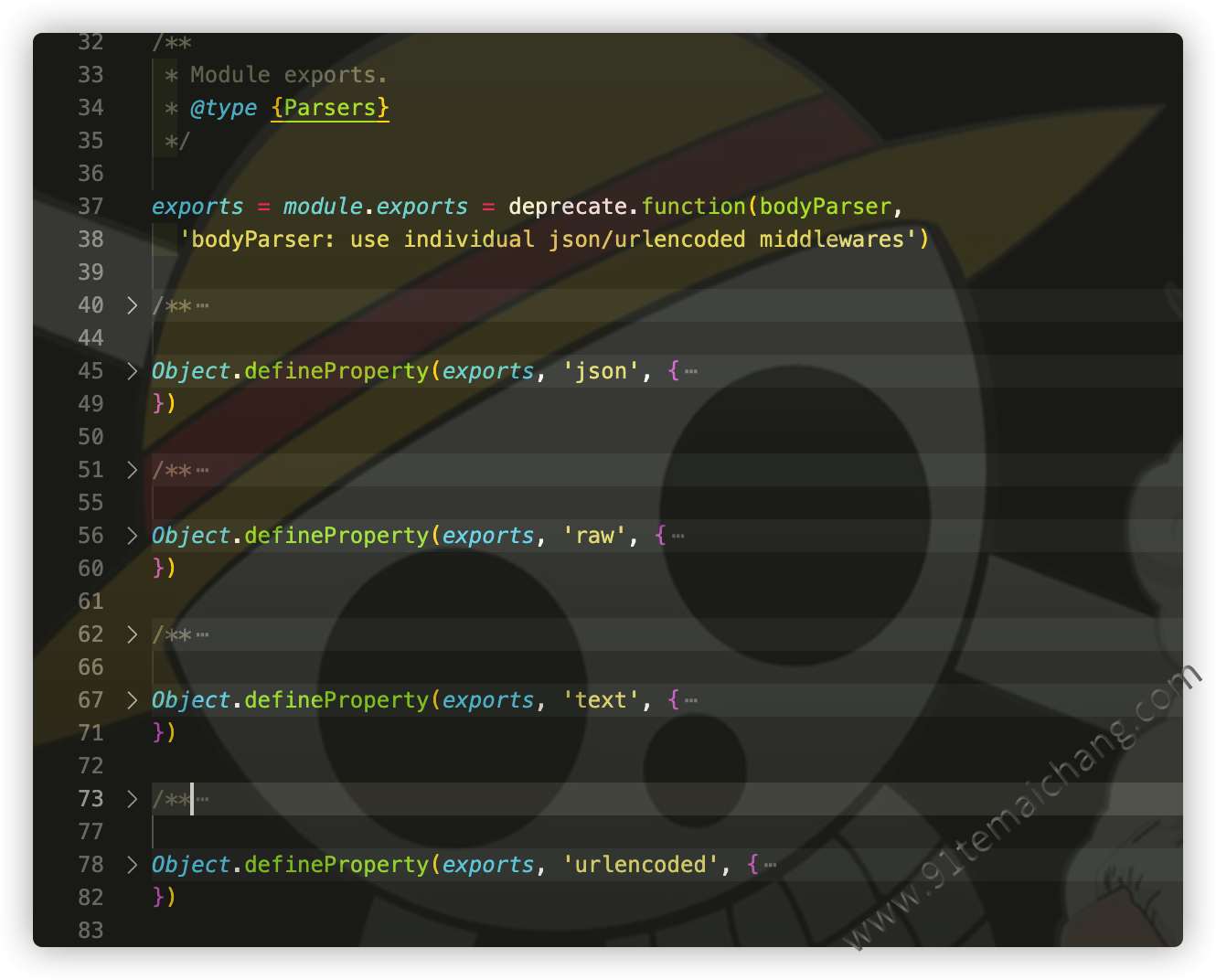
body-parser默认导出的是一函数对象,也就是我们可以通过bodyParser()函数,直接通过免传递参数的方式或者传递一type来实现对应解析器中间件的创建,如下代码所示:简单概括成一句话:从req中取出传递的数据,通过content-type类型采用对应的解析器,来解析,并存储到
req.body属性中,通过这种方式,然后最后再(req, res, next) => {}的方式返回出一函数出来,供使用者调用!
其底层调用了raw-body库,该库用于以 Buffer 或字符串的形式获取流的整个缓冲区,根据预期长度和最大限制验证流的长度,它是解析请求正文的理想选择。
body-parser各个解析器的参数描述
| 属性 | 类型 | 解析器独有 | 描述 |
|---|---|---|---|
| limit | number/string | 共有 | 待解析的内容大小,默认是100kb |
| inflate | boolean | 共有 | 默认值是true |
| reviver | function | 共有 | 与JSON.parse()方法中的第二个参数一致,是一个转换器,可用来修改解析生成的原始值 |
| strict | boolean | 共有 | 默认值是true |
| type | string | 共有 | 默认值是'application/json',用于确定中间件将解析的媒体类型 |
| verify | function | 共有 | 验证选项,verify(req, res, buf, encoding),用于验证数据 |
| extended | boolean | urlencoded独有 |
默认值是true,扩展选项允许在使用 querystring 库(如果为 false)或 qs 库(如果为 true)解析 URL 编码数据之间进行选择。 “扩展”语法允许将丰富的对象和数组编码为 URL 编码格式,从而提供类似 JSON 的 URL 编码体验。 |
| parameterLimit | number | urlencoded独有 |
控制 URL 编码数据中允许的最大参数数。如果请求包含的参数多于该值,则会向客户端返回 413。默认为 1000。 |
从body-parser中可学习到的技能
- 通过
简单工厂模式动态生成不同的解析器,由解析器来提供对应的解析服务动作;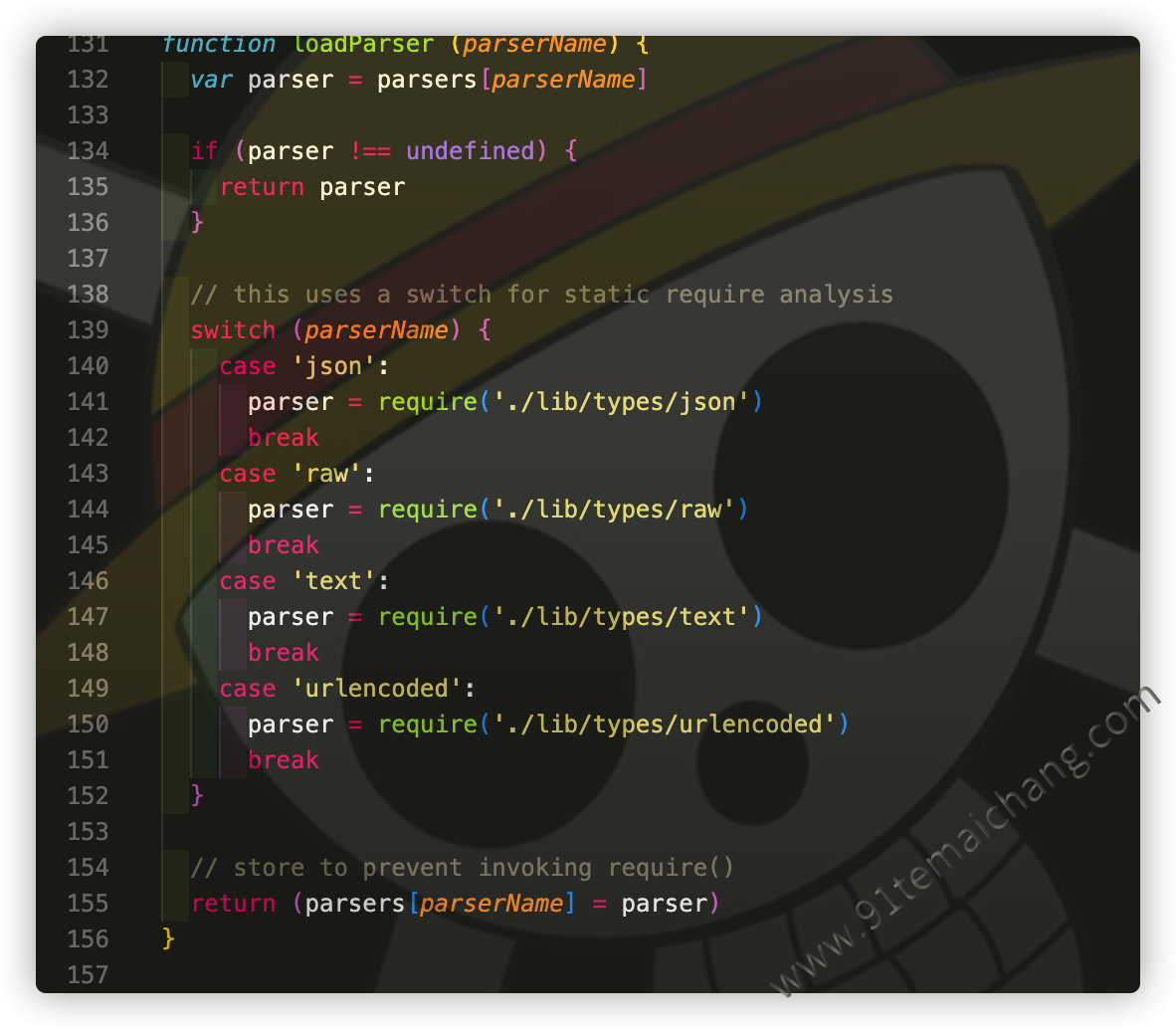
- 凭借着对象引用访问的原则,往
req对象中追加body属性,使得该属性可以在后续的其他中间件中被直接引用访问到! - 与
connect库类似,在函数中定义一函数,然后调用改函数,并且将此函数作为参数引用进行地址的传参,实现将函数的实现隐藏,并通过地址传递给其他内部函数