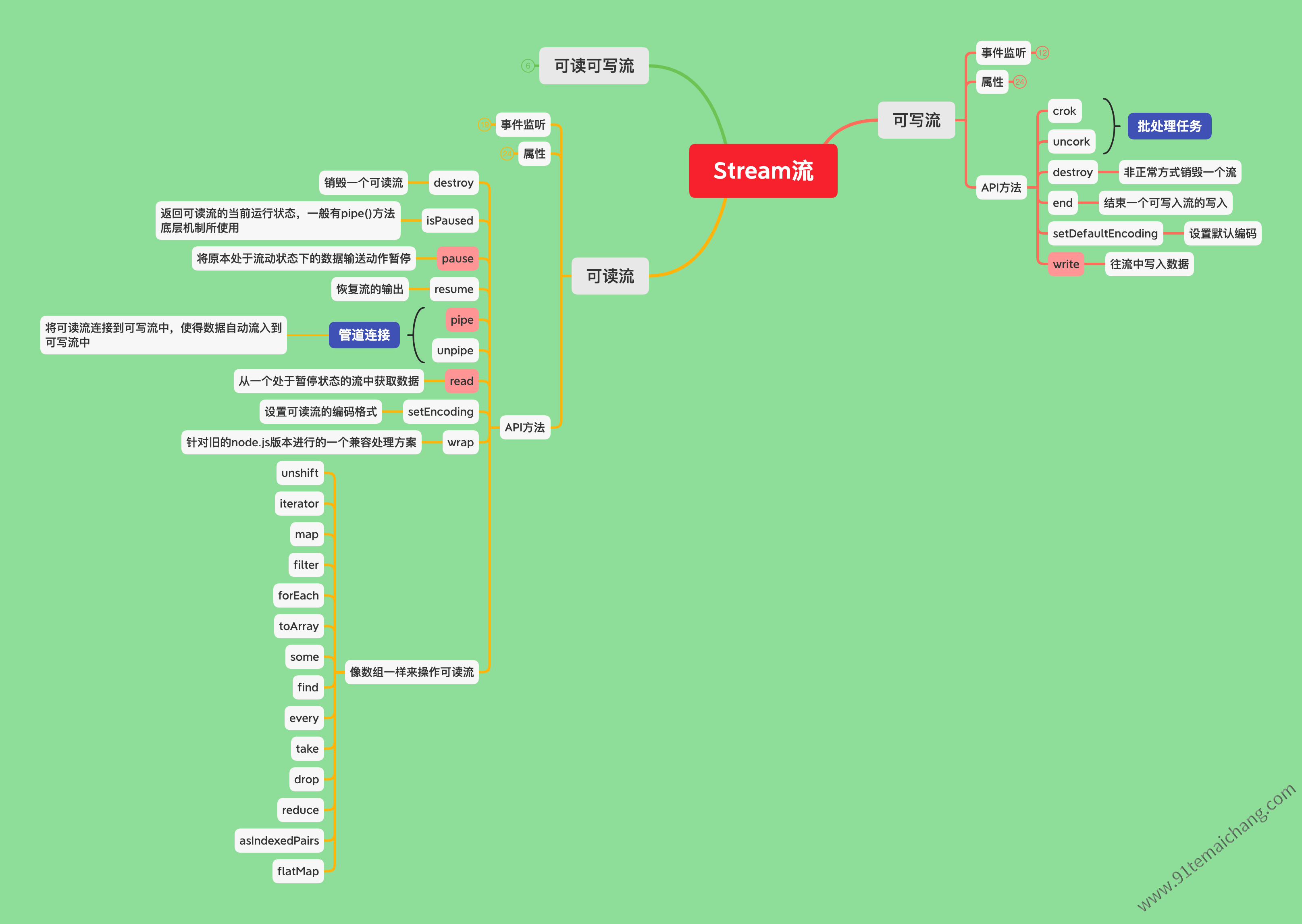
流
作为在node.js处理流数据的抽象接口,通过导入
node:stream来提供对流的一系列的操作,同时node.js也衍生提供了流的实例(比如有http请求流、process.stdout等等),一般的流具有以下的特性:
- 可读或者可写或者两者兼而有之;
- 都属于EventEmitter的实例,因此可提供对应的监听器与发起事件响应的能力;
 在流中,定义了一些处理数据的基本操作,如读取数据,写入数据等,程序员是对流进行所有操作的,而不用关心流的另一头数据的真正流向。流不但可以处理文件,还可以处理动态内存、网络数据等多种数据形式
在流中,定义了一些处理数据的基本操作,如读取数据,写入数据等,程序员是对流进行所有操作的,而不用关心流的另一头数据的真正流向。流不但可以处理文件,还可以处理动态内存、网络数据等多种数据形式
流的分类
在node.js中根据其特性,提供了以下四种类型的流:
- Readable: 可以从中读取数据的流(比如
fs.createReadStream()函数所创建的流);- Writable: 可以写入的流(比如
fs.createWriteStream()函数所创建的流);- Duplex: 同时支持读取与写入的流(比如:net.Socket);
- Transform: 在Duplex上包装实现的修改或转换的包装流(比如: zlib.createDeflate) 不同的类型的流各自用来提供不同的API来进行操作。

在计算机中操作和读写流,关键在于操作缓冲区,那么什么是缓冲区?为什么要使用缓冲区?
 缓冲区:是计算机开辟的一块(限制大小)的临时空间,用来存储读/写的数据的区域。
缓冲区:是计算机开辟的一块(限制大小)的临时空间,用来存储读/写的数据的区域。
 一般的,我们在读写文件(流)的时候,不可能每读一个字节就展示,而是将读取到的数据进行一个积累存储,这样子能够使得程序的运行效率更高,减少对系统I/O库函数的调用,因此提供了缓冲区来临时存放!!
一般的,我们在读写文件(流)的时候,不可能每读一个字节就展示,而是将读取到的数据进行一个积累存储,这样子能够使得程序的运行效率更高,减少对系统I/O库函数的调用,因此提供了缓冲区来临时存放!!
 根据其使用场景,一般的缓冲区
根据其使用场景,一般的缓冲区  几种不同类型的缓冲区:
几种不同类型的缓冲区:
 全缓冲区: 缓冲区中缓存的数据
全缓冲区: 缓冲区中缓存的数据  了,才会调用I/O库函数,对于读操作,如果晓得读取的字节数就等同于缓冲区的大小,或者文件的文件
了,才会调用I/O库函数,对于读操作,如果晓得读取的字节数就等同于缓冲区的大小,或者文件的文件\0才进行实际的I/O操作;
 行缓冲区: 直到遇到了换行符
行缓冲区: 直到遇到了换行符\n,才调用I/O操作,比如有目前的stdin或者stdout;
 无缓冲区: 数据激励读入或者立即输出到外部文件或设备,比如目前的
无缓冲区: 数据激励读入或者立即输出到外部文件或设备,比如目前的stderr就属于采用了这种类型的缓冲区,一旦 任何的异常错误,就立即反馈输出到控制台
通过上述关于缓冲区的学习,我们可以整理 的关于流在读、写的过程中的一个工作过程:
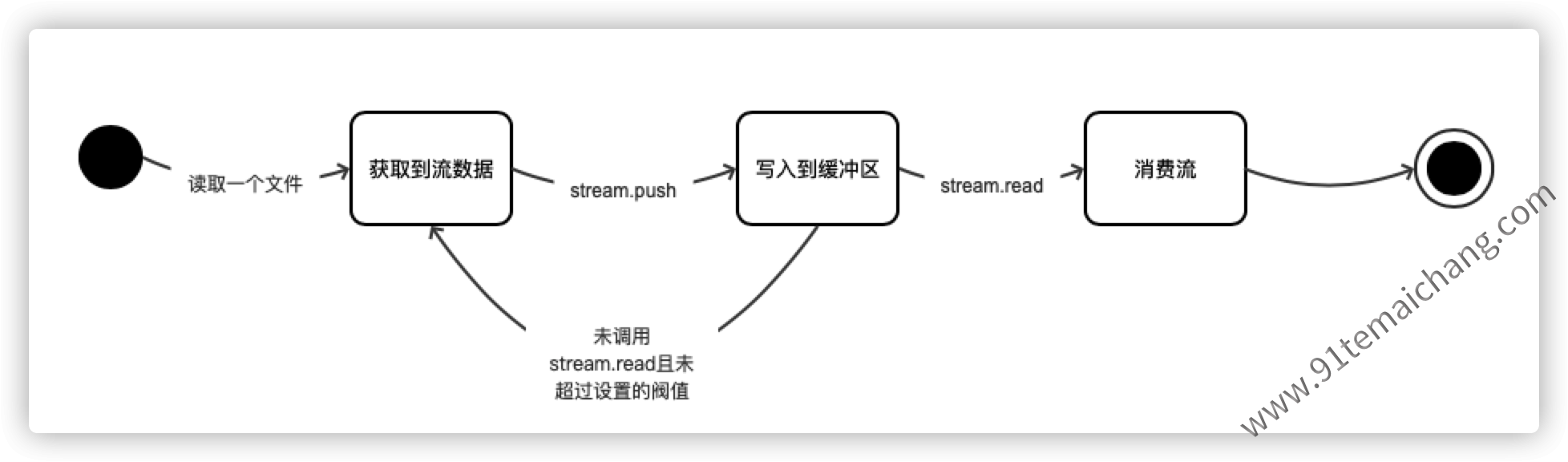
关于写入流的工作消费过程,也是雷同。而其中这里的阀值,而不是一个限制:它指示流在停止请求更多的数据之前缓冲的数据量,通常不强制执行严格的内存限制!!
对于同时拥有可读、可写流的Duplex与Transform,则是拥有着两个流缓冲区,各自进行该缓冲区的管理!!
流的使用
几乎所有的node.js应用,都以某种方式来使用着流,比如有
const http = require('node:http');
const server = http.createServer((req, res) => {
let body = '';
req.setEncoding('utf-8');
req.on('data', chunk => {
body += chunk;
});
req.on('end', () => {
try{
const data = JSON.parse(body);
res.write(typeof data);
res.end();
}catch(er){
res.statusCode = 404;
return res.end(`error: ${er.message}`);
}
});
});
server.listen(1337);
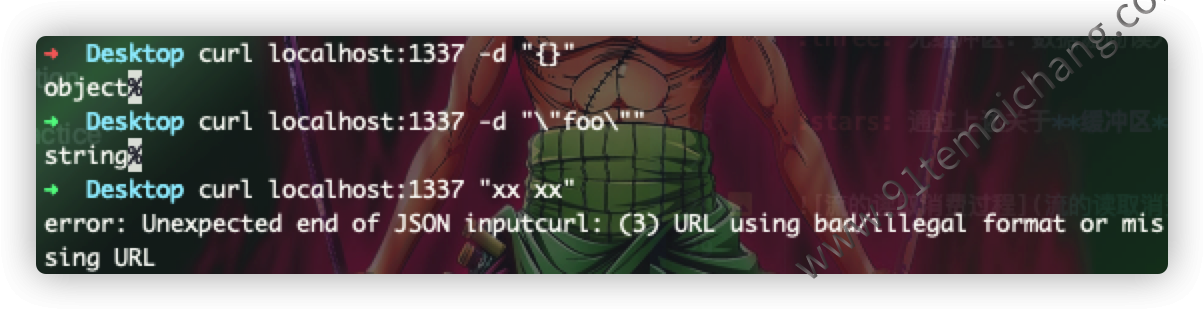 上述代码通过
上述代码通过http模块,来创建了一个http服务对象,通过传递的参数构造方法中的req以及res,来实现对流的操作,
req通过事件监听on来实现对data、end事件进行监听,res通过write以及end动作往流中写入数据!
由于可写流与可读流都继承EventEmitter对象,因此对流的读写操作可以直接通过事件来处理,而无需显示定义node:stream,仅需简单调用
即可,  除非是需要自定义流的类型,才需要进行定义
除非是需要自定义流的类型,才需要进行定义node:stream
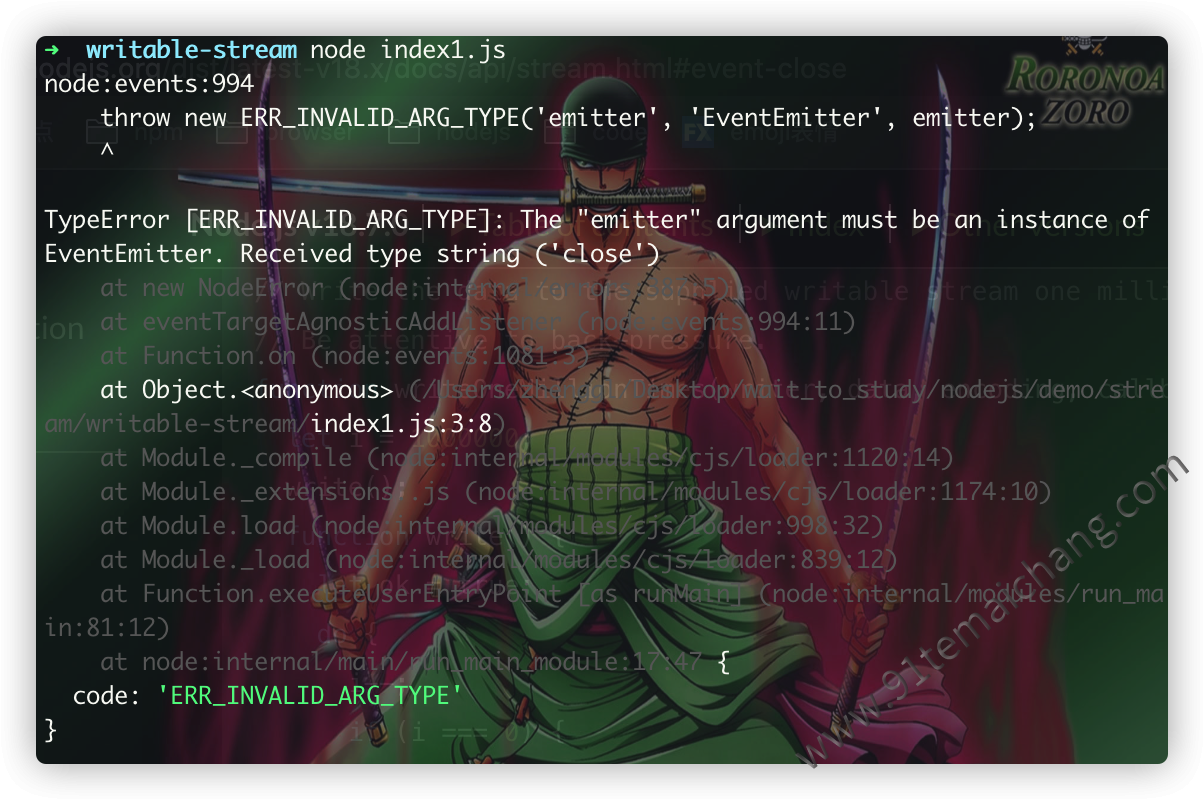
对流的错误使用
流就相当于是java中的abstract抽象类,不能直接调用,而是必须要在其实例对象上来使用的 对于流的使用,不能直接与其他的node模块一样引用依赖后,直接在引用的依赖上来调用其api,这样子将会导致异常的发生,如下代码所示:
const stream = require('node:stream'); stream.on('close', res => { console.info(res); }); stream.write('123');
可读流
可读流是对消费数据源的抽象。 是一个
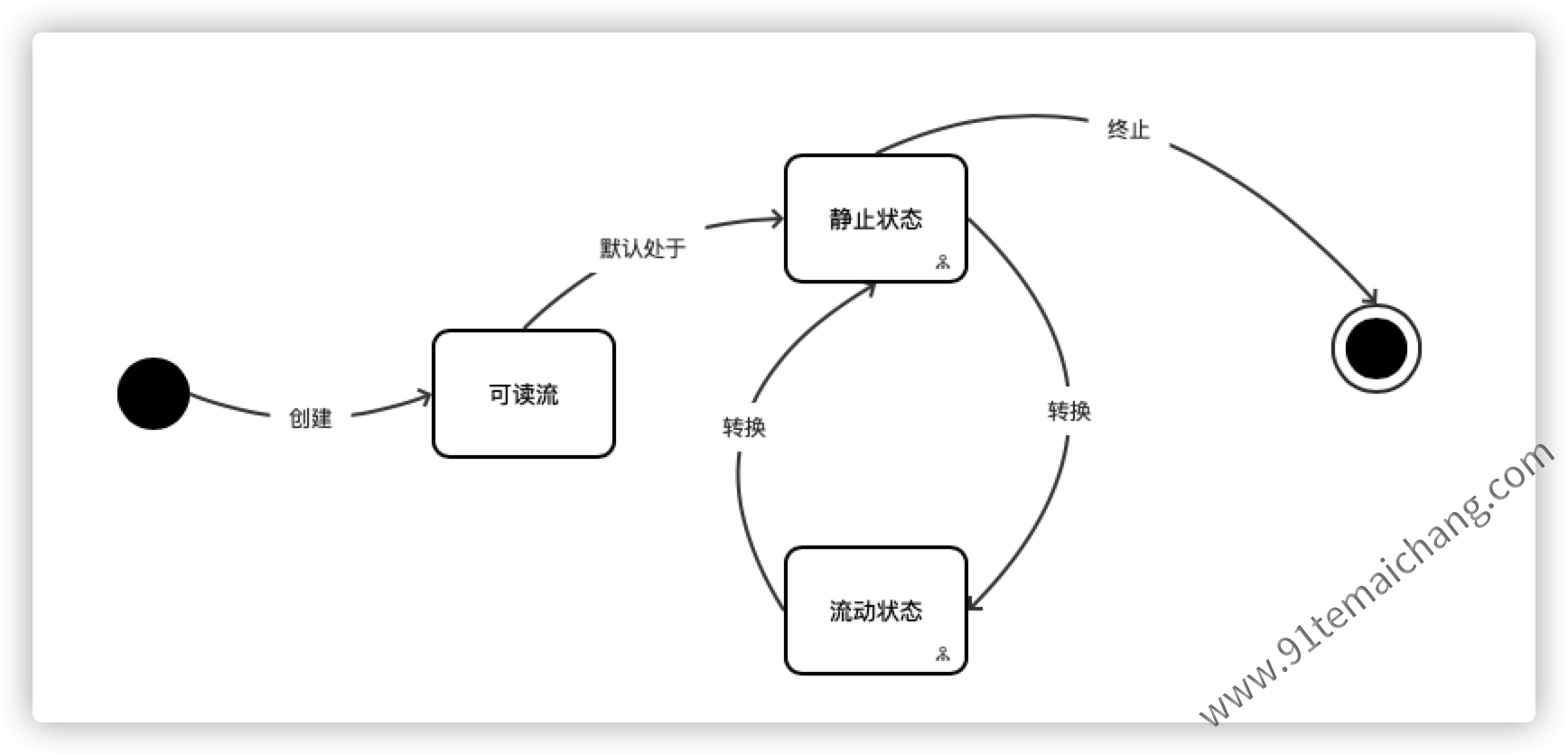
"抽象类"的集合,不能直接使用,需要"实例化"。 在node.js环境中,一般client http response、server http request、fs read stream、zlib stream、crypto stream、TCP socket、child process stdout和stderr、process stdin可读流在node.js环境中以两种状态模式来切换运行,保证流数据的正常获取的,如下图所示:
- 流动模式:在该模式下,数据自动从底层系统获取,并通过接口API提供给node模块;
- 暂停模式:在该模式下,数据处于停止流动状态,这个时候必须通过
显示的read()方法来获取数据
那么,我们应当怎样才能从流中获取到数据呢?
"容器"来容纳获取到的数据,否则数据意味着被缓存到缓冲区或者被抛弃掉,切换的过程如下图所示:
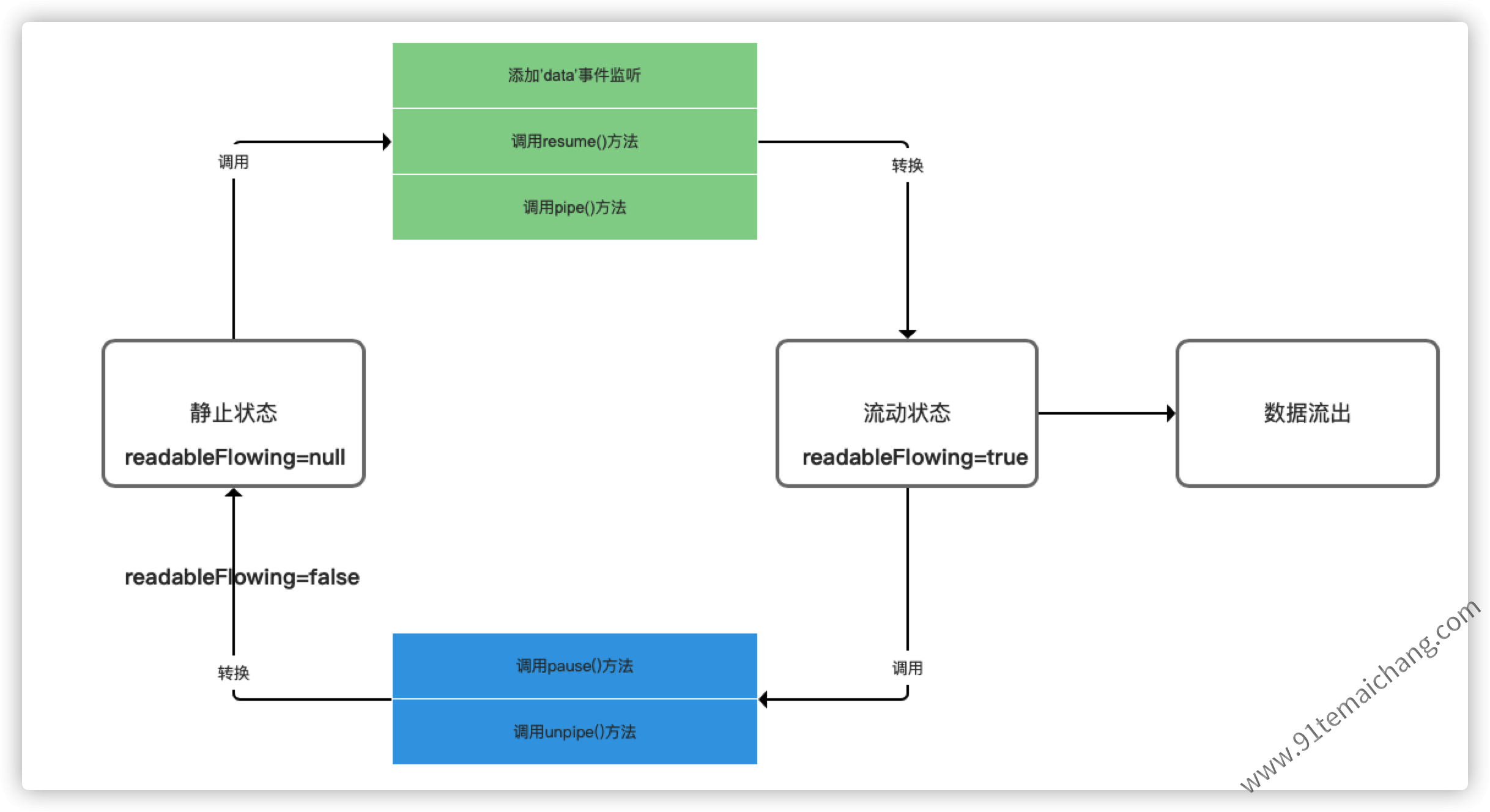
关于可读流的使用,需要 以下几个点需要注意的:
- 在可读流提供数据前,并不会生成数据,而如果可读流被禁用或者取消,则将尝试停止生成数据;
- 如果将流切换到流动模式,而且这个时候并没有设置处理数据的消费者,这个时候生成的数据将会丢失;
- 添加
readable事件监听后,会使流处于暂停状态,而且这个时候必须通过read()方法来读取数据。
 这里应该发现
这里应该发现  一个属性
一个属性readableFlowing,代表当前流的一个流动状态,其实上面的关于流的状态也是基于这个属性的变换来演变的,流的流动或静止取决于readableFlowing属性值的变换,
该属性 个值(null、true、false),方法的切换,其实本质上是readableFlowing值的变换!!
关于可读流,按照上面所说的,其实它是一个抽象的类,将流中的_read以及_destroy方法给抽象出来,给子类去实现,来满足子类仅做数据的读取以及销毁的动作,也就是 假如我们自定义了一个可读流的话,
是否意味着我们的重载方法将会被stream机制所调用,要验证这一个想法,可以按照 的方式来实例化一个流:
const { Readable } = require('node:stream');
const readable = new Readable();
readable._read = function(){
console.info('调用了子类的_read方法')
}
readable._destroy = function(){
console.log('调用了子类的_destroy方法');
};
readable.on('readable', () => {
console.info('进入到了readalbe回调函数中了');
});
readable.on('end', () => {
console.info('进入到了end回调函数中了');
})
setTimeout(() => {
readable.destroy();
}, 1000);
 通过 上面的代码输出结果,可以证明我们的猜想是正确的:
通过 上面的代码输出结果,可以证明我们的猜想是正确的:
可读流控制数据的流动,本质上调用的是read()方法,而read()方法在执行的过程中调用的是实例的
_read()方法,然后再去触发readable事件!!!
可读流事件监听
close: 当流或者任何底层资源(比如文件资源)被关闭时,发出这个事件,表示不会再发生任何计算事件,与可写流类似,要使一个可读流在结束的时候 自动发起
close事件,则需要在创建这个可读流的时候,配置其emitClose属性const fs = require('node:fs'); const readable = fs.createReadStream('./xxx.txt', {emitClose: true}); readable.on('close', () => { console.info('收到了自动关闭的操作'); }); readable.resume(); console.info(readable.read());
data
每当将数据的所有权转交给消费者时,就会触发该回调方法,这里的
"转交"过程其实就是on('data')、pipe()、resume()方法执行的瞬间,或者时在暂停模式下的流调用read()方法,并且能够从该方法中返回数据时,也会触发这个回调方法!! 简而言之,就是流处于流动或者从中获取数据时,触发该方法
简而言之,就是流处于流动或者从中获取数据时,触发该方法const fs = require('node:fs'); const readable = fs.createReadStream('./xxx.txt', {emitClose: true}); readable.on('data', chunk => { console.info('data读取到数据是:', chunk.toString()); });
end: 当流中没有更多的数据要消耗时,发出end事件
readable: 当流中有可读的数据时,或者已经读取到了流的末尾时,会触发
readable事件,代表流具有新信息,若数据可用则返回该数据const fs = require('node:fs'); const readable = fs.createReadStream('./xxx.txt', {emitClose: true}); readable.on('readable', () => { console.info('触发了readable'); let data; while((data = readable.read()) !== null){ console.info('readable读取到的数据', data.toString()); } }); 从 我们可以看出,设置了
从 我们可以看出,设置了readable事件使得流中的数据被读入缓冲区中,而且在数据可读之前调用了一次该方法,然后 从数据中读取的过程不调用该方法,到了事件的末尾的时候,又在调用该方法!
假如data与readable事件同时存在的时候,这个时候的事件回调顺序应该是怎样的呢?
const fs = require('node:fs');
const readable = fs.createReadStream('./xxx.txt', {emitClose: true});
readable.on('data', chunk => {
console.info('data读取到数据是:', chunk.toString());
});
readable.on('readable', () => {
console.info('触发了readable');
let data;
while((data = readable.read()) !== null){
console.info('readable读取到的数据', data.toString());
}
});
 从 代码我们可以看出
从 代码我们可以看出readable事件就像是包裹在data事件外面的一个事件一样:
数据准备好可以读取了 调用readable事件代表开始 调用data事件 调用readable事件代表结束
可读流属性
- readable: boolean值代表是否能够
安全的调用read()方法,意味着当前流可读,未被销毁或者异常退出,一般用于在实际编码中,作为流可读前的一个检测,可减少在代码中写bug的情况
可读流方法
销毁流(
destroy([error]))销毁一个可读流,传入的error可选参数,代表是否要触发
error事件,同时触发close事件(这取决于这个可读流创建时是否配置了closeEmit属性,默认为true), 执行该事件后可读流资源将被释放,而且任何进一步地对当前可读流的操作都是徒劳,相当于调用对应的操作时直接被return了,如下所示: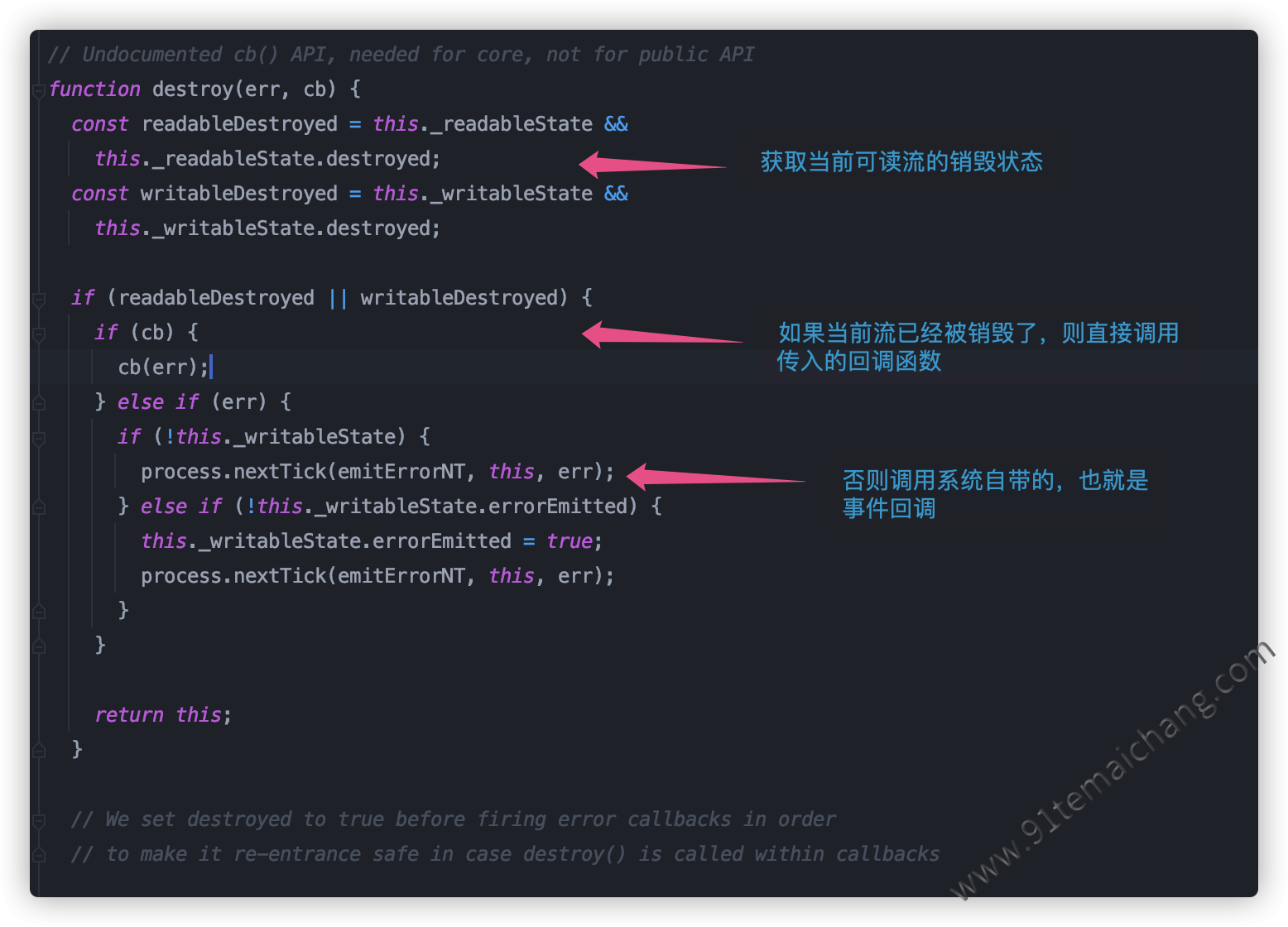
const fs = require('node:fs'); const readable = fs.createReadStream('./xxx.txt', {emitClose: true}); readable.on('error', err => { console.info('收到了销毁动作', err.message); }); readable.destroy(new Error('销毁异常信息')); readable.destroy(new Error('新的销毁异常'), err => { console.info('之前已经销毁过了,直接异常', err); }); readable.read(10, err => { console.info('读取异常', err); }); 我们可以看出
我们可以看出readable.read()方法在销毁之后,并没有任何的作用了,其实是通过对可读流对象中的状态进行赋值,统一根据 可读流中的状态值变量进行操作前的一系列判断即可满足这个逻辑!!而对于是否需要发起事件回调,则按照 的逻辑来执行:
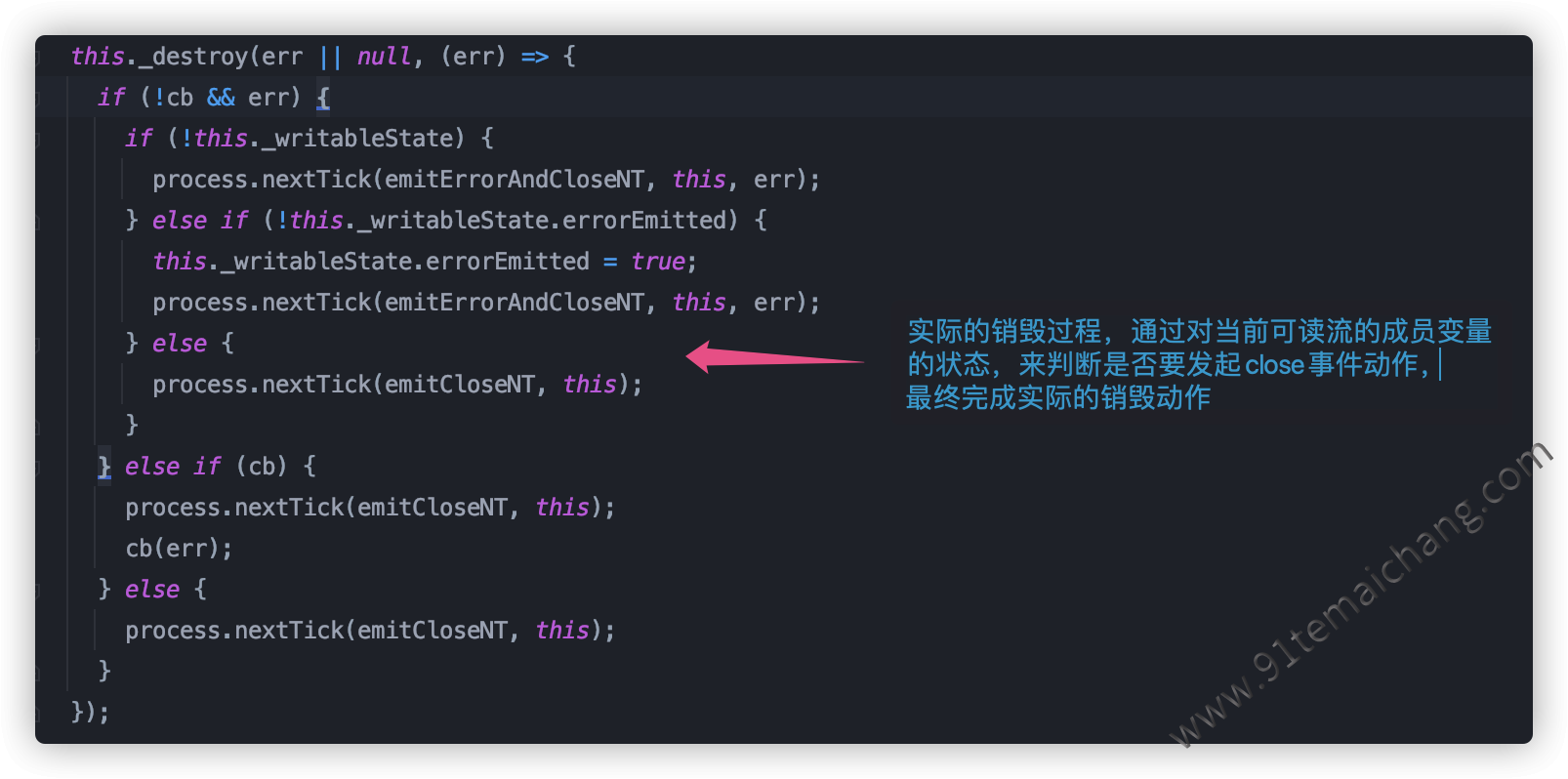 在实际的编码中,假如我们需要自定义一个流实例的话,需要对其
在实际的编码中,假如我们需要自定义一个流实例的话,需要对其_destroy方法进行重写,来作为数据释放清理动作!!暂停与恢复数据输送(
pause()与resume())pause()将原本处理流动状态下的数据的输送动作停止,
data事件也暂停接收数据,这时的数据将保留在缓冲区中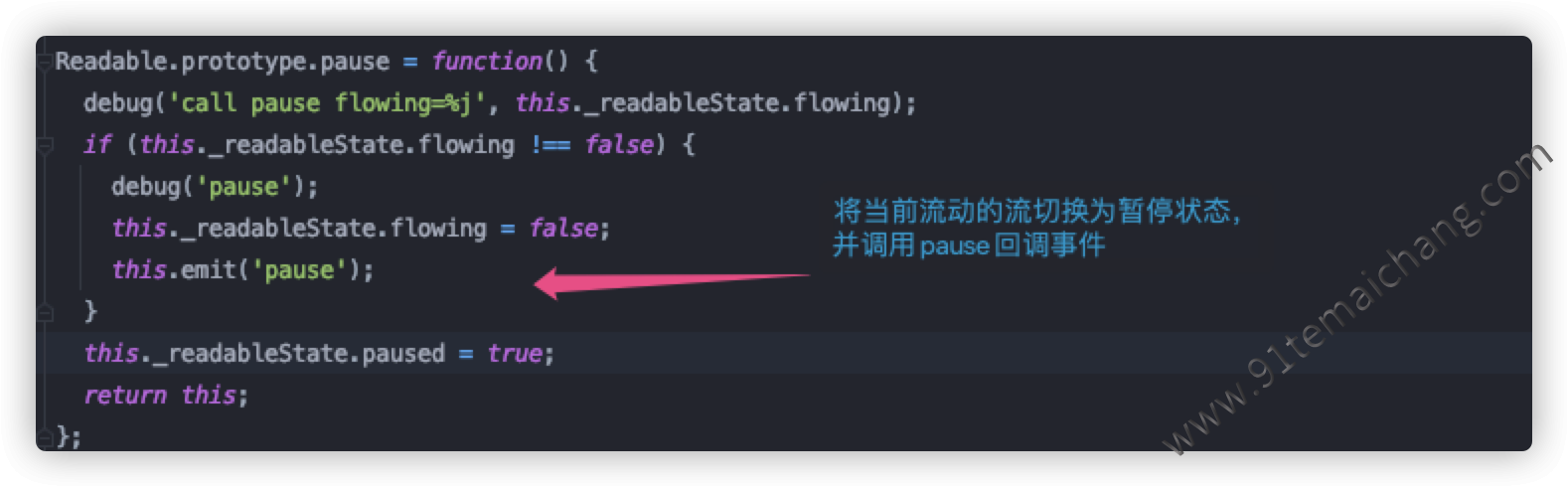 而resume()则是将设置为暂停状态下的流恢复为流动状态,继续数据的输出
而resume()则是将设置为暂停状态下的流恢复为流动状态,继续数据的输出
const fs = require('node:fs');
const readable = fs.createReadStream('./xxx.txt', {emitClose: true});
readable.on('data', chunk => {
console.info('data读取到数据是:', chunk.toString());
readable.pause();
console.info('当前数据读取动作将暂停,这里设置3秒后恢复');
setTimeout(() => {
readable.resume();
}, 3000);
});

pause与resume是一般是成对的存在,主要用于手动控制流的一个流动状态, 来看一下关于resume的执行过程,本质上也是控制流变量的值,并通知触发对应的事件回调,来完成流的数据的自动流出的。
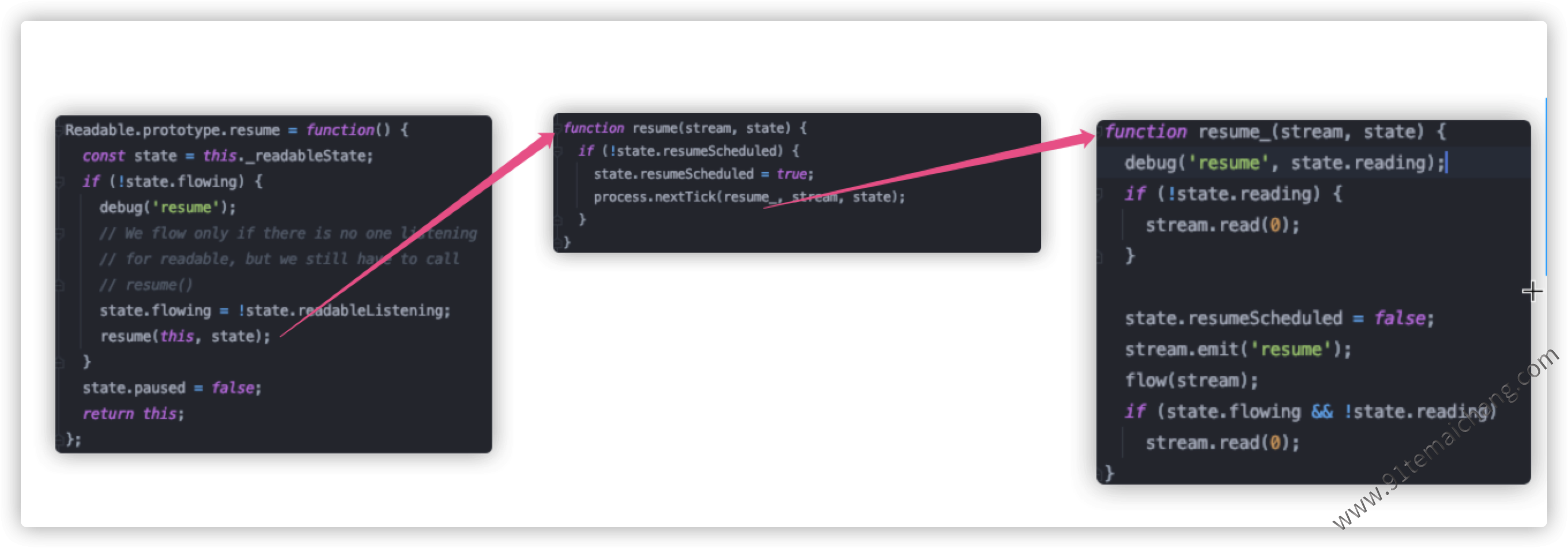
关于pause()方法在使用过程中,与readable事件监听器存在一定的冲突: 一旦 readable事件监听了,那么这个时候怎么调用pause()方法都没有用!因为readable事件一旦设置了,当数据可以流出的时候,
就立马触发readable以及data事件与pause()方法设计理念上相悖!!
假如可读流设置了一个readable事件监听,那么这个resume()方法调用将无效!!!
- 管道输送(
pipe()与unpipe())在介绍关于管道的相关知识点时,先对比一下
两者的一个使用情况:
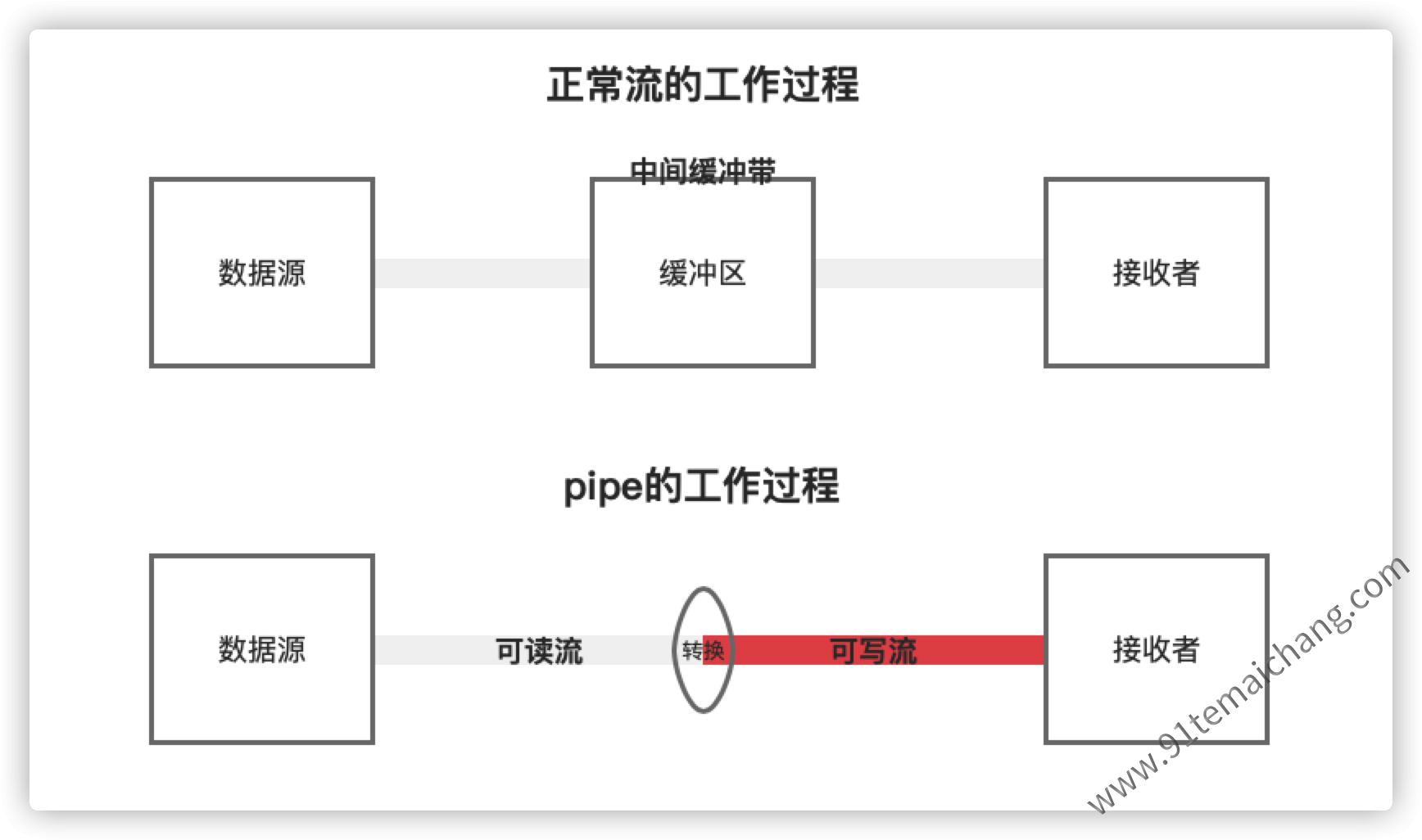 从 这里我们可以看出
从 这里我们可以看出pipe其实是将一个可写流怼到可读流外面,将可读流给包装起来,使得原本的可读流自动切换为流动状态,将数据输送到可写流中const fs = require('node:fs'); const process = require('node:process'); const readable = fs.createReadStream('./xxx.txt', {emitClose: true}); readable.pipe(process.stdout); 这里已经实现是将可读的文件流中对接到标准输出流中!
这里已经实现是将可读的文件流中对接到标准输出流中!
思考是否可以将多个流怼到同一个可写流中呢?
这是允许的,因为pipe()方法,返回的一个指向目标可写流,而可写流其实它也 一个pipe()方法,使得可以直接怼到另外的一个目标可写流中,比如有 这样的一个情况:
const fs = require('node:fs');
const zlib = require('node:zlib');
const r = fs.createReadStream('xxx.txt');
const z = zlib.createGzip();
const w = fs.createWriteStream('xxx.txt.gz');
r.pipe(z).pipe(w);
当readable可读流发出end事件时,被怼的可写流writable也能够同样接收到end事件,假如我们想要使writable不必接收到end事件,那么可以在可读流调用pipe方法的时候,传递这个end=false的参数,
以便于使得该writable在可读流end的时候,保持可写流继续处于可写状态,以便于追加其他的数据到可写流中,这里有一个例外需要 的是process.stderr与process.stdout两个可写流,在使用了pipe的时候,
它并不会因为可读流的end,导致其可写流也收到end事件,它会一直保持打开状态,直至node进程关闭!
这里 一个问题需要注意的是:如果可读流在pipe()的过程中发生错误被关闭了额,那么被怼的可写流依然是处于打开的状态,这个时候,就需要在可读流异常的时候做资源的回收、关闭未关闭的可写流,
这里可以在可读流的异常回调中进行可写流的关闭来释放掉没用到的资源
 在使用了pipe()方法之后,我们还可以使用
在使用了pipe()方法之后,我们还可以使用unpipe()方法来对可写流进行拆卸,而可选的参数则代表是上次安装的可写流对象,不传递则代表拆卸所有的可写流!!
静止状态数据读取(
read([size]))从缓冲区中读取数据并返回,若无数据,则返回为null,默认情况下使用Buffer对象返回,除非设置了enCoding,或者是在调用
read()方法时,对其结果进行toString()转换一下,来获取对应的字符串,可选的参数size代表一次从缓冲区捞多大的数据。read()方法只能在处于暂停模式下的流使用,而在流动模式下,其内部是调用的read()方法来获取数据,最终调用的是实例自身的_read()方法来获取的。 一般情况下,简单通过创建一个可读流(默认状态下为静止模式),通过显示地调用read()方法来读取的数据,往往得到的结果是null,因为在这个时候,流还没有"准备好",那么我们怎么晓得流已经准备好可以从缓冲区中捞数据了? 通过与readable监听事件的捆绑,在该事件的回调中来通过read()方法获取数据,而且这里还需要根据这个缓冲区的类型,配合while循环来持续获取数据,因为read()获取到的数据是不连续的!!
可写流
数据写入目的地的抽象集合对象。 在node.js中的实例一般
http request、http response、fs write stream、zlib stream、crypto stream、TCP sockets、child process stdin、process.stdout、process.stderr,其中有一些是实现了可写流接口的包装流;
- 获取可写流(通过创建或者是直接获取);
- 通过其提供的api往流上写数据;
- 根据缓冲区的不同实现不同场景下数据的写入;
- 结束写入的动作
可写流监听事件
close: 当流及其任何底层资源(例如文件描述符)已关闭时,将发出该事件。该事件表明不会再发出任何事件,也不会发生进一步的计算,一般该回调的调用取决于创建它的选项中是否带入了
emitClose属性const process = require('node:process'); process.stdout.on('close', res => { console.info(res); }); process.stdout.write('123'); process.stdout.end('456'); 这种方式在流结束的时候,并无调用
这种方式在流结束的时候,并无调用close事件,因为这个事件的调用取决于流的创建是否传递了对应的选项属性,如下代码所示:const fs = require('node:fs'); const fileStream = fs.createWriteStream('./xxx.txt', { emitClose: true, autoClose: true }); fileStream.on('close', res => { console.info('文件流自动结束', res); }); fileStream.write('555'); fileStream.end('88'); 第二个例子采用了
第二个例子采用了emitClose属性,控制流在未被使用的情况下,自动调用close监听事件!!!error: 如果在写入或传输数据时发生错误,则会发出该事件
finish: 方法被调用后触发,并且所有数据都已刷新到底层系统
const fs = require('node:fs'); const fileStream = fs.createWriteStream('./xxx.txt', { emitClose: true, autoClose: true }); fileStream.on('close', res => { console.info('文件流自动结束', res); }); fileStream.on('finish', res => { console.info('文件流写入完毕', res); }); fileStream.write('555'); fileStream.end('88'); 这里当调用的
这里当调用的end方法的时候,将自动调用finish监听事件!!!pipe与unpipe
当将一个可写入流
怼到可读取流的管道上是调用pipe事件,从可读取流上移除时调用unpipe事件const process = require('node:process'); const fs = require('node:fs'); const fileStream = fs.createWriteStream('./xxx.txt'); fileStream.on('pipe', src => { console.info(src); }); process.stdin.pipe(fileStream); 这里将一个文件写入流怼到可读取流中数据等待(drain)
如果我们使用了
write()方法来写入数据到流的时候,返回的false,则代表当前写入流繁忙,这个时候就会触发drain事件当数据被写入到流中!!
可写流属性与方法
批处理(writable.cork()、writable.uncork()、writable.writableCorked)
在nodejs中可以采用
writable.cork()方法,强制将所有的数据缓存到内存中,然后当调用writable.uncork()或者writable.end()方法的时候,将缓冲区中的数据强制刷新出来, 其实这里也是批处理实现的一种方式,将原本需要几小块的动作,同时写入到流中。stream.cork(); stream.write('some '); stream.write('data '); process.nextTick(() => stream.uncork()); 假如写了多个cork()函数调用,那么对应的需要有对应数量的uncork()函数,来对应清空缓冲区的数据销毁流(
destroy(error))用于销毁一个流,可以往其函数参数传递一个error对象,同时将会发起一个
close事件推送, 假如这个时候有正在写入的异步I/O操作的时候,将会直接将当前的操作给中止掉,如果我们想要保证原本的数据能够正常地写入的话,那么我们可以采用的方式是使用write()或者是end()方法,以免数据出现丢失!!!const fs = require('node:fs'); const myStream = fs.createWriteStream('./xxx.txt'); const err = new Error('xxx error!'); myStream.write('123123'); myStream.destroy(err); myStream.on('error', err => { console.info(err); });
写入数据(write(chunk))
关于该api的一个使用方式如下:
boolean result = writable.write(chunk[, encoding][, callback]); 参数说明
chunk: 等待被写入流的数据;
encoding: 写入的数据编码格式;
callback: 当数据从缓冲区被刷到流中的时候触发该回调函数,如果在写入的过程中发生了错误了,那么异常将会从该函数的第一个参数返回;
返回值:boolean值,如果流希望调用其他代码在继续写入其他数据之前等待drain事件,则返回false,否则返回true
一般情况下,我们往流写入数据,一般数据如果不大于缓冲区设置的阀值的话,那么这个write方法写入成功,并返回了true,但是如果这个时候缓冲区的阀值小于要写入的数据大小的话,这个时候,将会将这个写入动作挂起,
等待下一步的尝试,直到发出了drain事件为止!!!
了 的一个写入数据的过程探索,我们可以更好地来编写关于写入数据到流的比较好的实践:
在写入数据到流中的时候,根据其返回值true/false来判断当前是否允许写入数据到流中,可以配合drain事件监听,来实现这个写入数据的最佳实践(虽然nodejs环境会自动调用),假如这个时候执行的时候返回的结果值
为false,那么nodejs将或自动缓存数据到缓冲区中(也就是内存缓存),一旦内存也不够缓存的时候,这个时候就会内存溢出,因此在写超大数据的时候,需要考虑这一点!!!
如果待写入的数据是可变的(实际情况也经常如此),建议是将数据的获取转换为一个可读的流,然后借用pipe方法,将可读的流转接到可写的流中,实现将动态变换的数据写入到流中!!
const process = require('node:process');
function write(data, callback){
if(!process.stdout.write(data)){
console.info('当前还不能够写入数据到流中');
process.stdout.once('drain', callback);
}else{
process.nextTick(callback);
}
}
write('hello,node.js', () => {
console.info('完成实际的写入动作');
});
可读可写流(全双工流)
Duplex为同时实现了可读流与可写流接口的流对象 一般有
TCP sockets、zlib streams、crypto streamsTransform则为特殊的Duplex,一般是其输出流与输入流
allowHalfOpen属性
标识用于控制当可读流结束时,是否自动结束可写流,默认时true,表示自动结束!
可读可写流API方法
finished
当流不再可读或者可写或者发生错误或者关闭事件不满足的情况下接收警报,其调用组成结果如
所示:
const cleanup = stream.finished(stream[, { error: boolean, readable: boolean, writable: boolean, signal: AbortSignal }], callback);参数说明 :- error: 默认为
true,表示调用emit('error', err)被视为已完成,false则相反; - readable: 默认为
true,表示在流结束时不可读,false则相反; - writable: 默认为
true,表示在流结束时不可写,false则相反; - signal: 允许中止等待流完成
- callback:一个带 可选错误参数的回调函数
返回值:返回清除所有已注册监听器的清理函数,也就是调用该函数将会清除所有的监听器!!
const stream = require('node:stream'); const fs = require('node:fs'); const rs = fs.createReadStream('./xxx.txt'); stream.finished(rs, { readable: false, callback: res => { console.info(res); } }, err => { if(err){ console.error('流停止出现异常了', err); }else{ console.info('流正常执行~'); } }); rs.resume();
- error: 默认为
pipeline
作为一模块方法,用于在流与生成器之间传递错误,并在管道输送完成时进行清理动作! 它
两种调用方式:
stream.pipeline(source[, ...transforms], destination, callback)stream.pipeline(streams, callback)
实现自定义流
从
继承的方式,来实现自定义的流,来满足于实际的开发需求,搭建更加灵活的流,一般需要实现的api如下: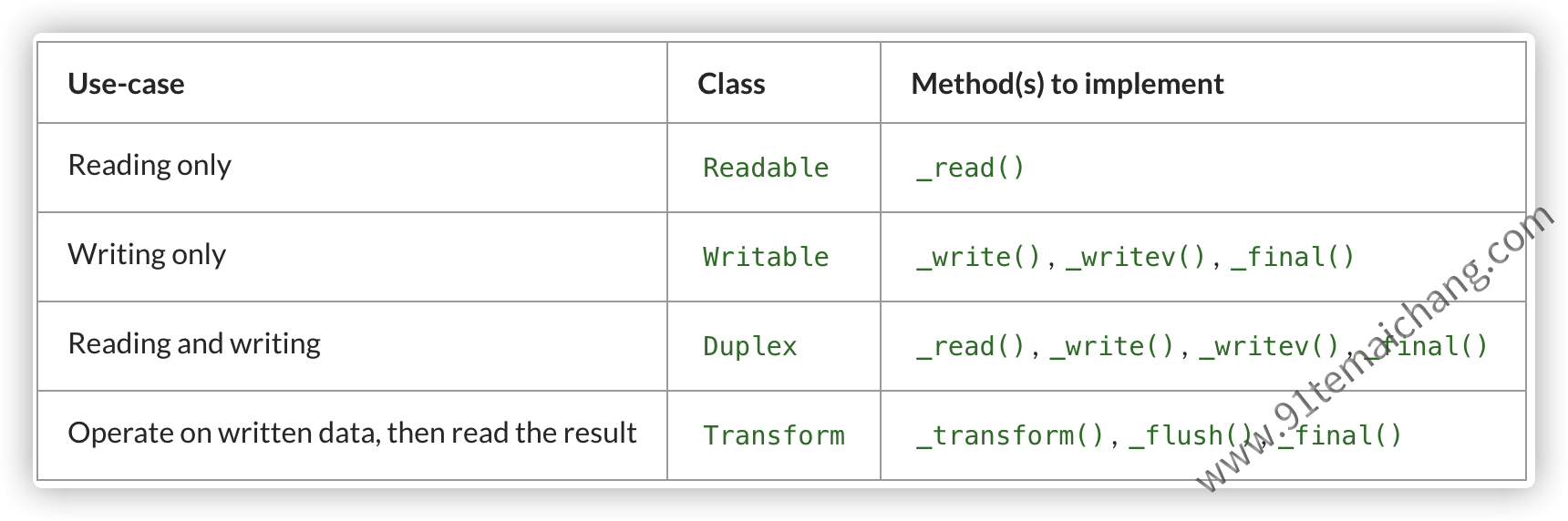
write()、end()、destroy(), 还有相关的事件监听也是被止重载的,因为这原本就是stream所提供的一个抽象编程的设计模式,将抽象的动作进行抽离,由 子类来实现,而在自身框架在实现过程中,通过调用子类的实现,来满足统一的资源管理、数据管控的目的!!!
小结
通过对流的使用,了解了关于可读流、可写流、全双工流他们在使用过程中需要注意的情况,而不是一来就直接怼其api,需要理解他们的api 与属性,在使用的过程中需要注意的点,理解stream是怎样将其属性与api给配合起来协同使用的,从而更加合理地来使用stream! 而当stream不满足实际业务编码的时候,还可以通过
继承的方式,来重载相关的api方法,达到实际的特殊场景的业务!!